
ChartBench
ChartBench: A Benchmark for Complex Visual Reasoning in Charts
Abstract
多模态大型语言模型(MLLMs)展现出令人印象深刻的图像理解和生成能力。然而,现有基准测试使用的图表有限,且与现实世界场景偏离,这对准确评估MLLMs的图表理解能力构成了挑战。为了克服这一限制,我们提出了ChartBench,这是一个专门设计来评估MLLMs在图表理解和数据可靠性方面通过复杂视觉推理的全面图表基准测试。ChartBench包括42个类别、2.1K个图表和16.8K个问答对。与以往的基准测试不同,ChartBench避免使用直接标注数据点的图表或元数据提示。相反,它迫使MLLMs利用图表固有的元素,如颜色、图例或坐标系统,来推导与人类理解相似的值。此外,我们提出了一个增强的评估指标Acc+,它无需劳动密集型的手工努力或基于GPT的昂贵评估就能够促进MLLMs的评估。我们广泛的实验评估涉及12个广泛使用的开源MLLMs和2个专有的MLLMs,揭示了MLLMs在解释图表方面的限制,并提供了宝贵的洞察,鼓励更仔细地审视这一方面。
1. INTRODUCTION
鉴于大型语言模型(LLMs)[Radford et al., 2021; Brown et al., 2020; Chowdhery et al., 2023; Touvron et al., 2023a]的突破性进展,多模态大型语言模型(MLLMs)[Li et al., 2023c; Liu et al., 2023b; Zhu et al., 2023]已成为多模态学习领域的主导方法,展现了强大的感知和推理能力。值得注意的是,MLLMs展现了对整体视觉语义理解的强大把握,并且甚至能够理解梗图中的幽默[OpenAI, 2023; Wang et al., 2023]。然而,MLLMs在有效阅读、理解和总结包含嵌入式图表的文章方面仍面临挑战[Masry et al., 2022; Han et al., 2023; Li and Tajbakhsh, 2023]。与通常基于可辨识物体、相对位置或交互关系来解释的自然图像不同,图表通过趋势线或颜色编码的图例等视觉逻辑传达细微的语义含义。它们以视觉格式提供详细且复杂的数据叙述。因此,评估MLLMs在理解这些视觉表示形式方面的图表理解能力和数据可靠性是至关重要的。
先前的工作,如ChartQA [Masry et al., 2022],试图解决这个问题,但遭受了一些局限性。1) 它们主要关注3种常规图表类型(例如,线图、饼图和条形图),忽略了更复杂的格式,如散点图或组合图表,这些在现实世界场景中同样普遍。健壮的MLLMs应能熟练处理多种图表类型。2) 它们严重依赖于点注释图表或作为文本提示的元表数据[Masry et al., 2022; Han et al., 2023]来评估MLLMs,这样它们可以轻易获得候选答案并忽略图表的视觉逻辑。3) 所采用的评估指标(伴随宽松误差范围的判断或填空题),可能产生夸大的基线性能,需要进行改进,以提高评估的客观性和精确性。
ChartBench 提供了全面的评估,覆盖了感知和概念两个方面。评估包括4种不同类型的图表问答任务:图表类型识别(CR)、值提取(VE)、值比较(VC)和全局概念(GC)(参见图3进行可视化)。为了确保严格和精确的评估,我们引入了一个新的度量标准Acc+,灵感来源于MME [Fu et al., 2023a]。Acc+度量标准要求MLLMs对基本断言的正面和负面观点都提供准确的判断。这种新颖的度量标准提供了两个优点。1) 它努力在正面和负面查询之间保持一致性,仅在真值(GT)上有所不同。这种预防措施最小化了由随机选择导致的幸运猜测的可能性,因为如果MLLMs未能理解图表,它们可能会对两种查询类型产生相同的响应。2) 负面查询的GT值来自同一图表内的其他数据,消除了不现实的情境,并增强了评估过程的有效性。
我们评估了12个主流开源和2个闭源MLLMs的零样本性能。研究发现表明,当面对复杂图表时,MLLMs通常表现出有限的推理能力,这引起了人们对它们数据解释可靠性的关注。即使是性能高的MLLMs,如GPT-4V [OpenAI, 2023],也需要多步骤的手工指导才能得出准确的答案,如附录所示。对ChartBench的详细检查揭示了MLLMs在图表上表现不佳的原因,突出了ChartBench的细致策划,以探索图表推理的细微差别。此外,我们提出了一种手工制作的思维链提示,称为ChartCoT(见图4),以指导MLLMs解释图表,类似于人类的理解。这种简单而有效的增强旨在刺激未来研究中更多创新性的提议。我们的贡献可以总结如下:
- 我们引入了ChartBench,显著扩大了图表类型的种类和数量。值得注意的是,ChartBench避免了直接标注数据点或使用表格数据作为文本提示,促进MLLMs通过视觉推理导出答案。
- 我们提出了一种新颖的Acc+度量标准,显著减少了随机猜测的情况,提供了一种更准确、更有效的评估方法。
- 我们提出了一个简单而有效的基线ChartCoT,指导MLLMs更类似于人类地解释图表。ChartCoT还显著提高了MLLMs的图表理解能力。
- 通过广泛的实验,我们证明了现有MLLMs在图表理解方面存在不足。这些发现揭示了优化未来MLLMs在这一方面的潜在方向。
2. Related Works
2.1 多模态大型语言模型(MLLMs)
自从Transformer [Vaswani et al., 2017]出现以来,大型语言模型(LLMs)得到了爆炸式的发展 [Radford et al., 2018; Brown et al., 2020; Zhang et al., 2022; Chowdhery et al., 2023; Touvron et al., 2023a,b]。通过指令调优,LLMs可以弥合自回归预测训练目标与遵循人类指令目标之间的差距 [Ouyang et al., 2022; Li et al., 2023a; Wang et al., 2022]。通过将LLMs扩展到多模态学习领域,MLLMs已成为主导方法。VisualGPT [Chen et al., 2022] 在使用LLMs作为视觉-语言(V-L)解码器方面显示出有希望的结果。Flamingo [Alayrac et al., 2022] 在预训练的LLM内对来自冻结视觉编码器的特征进行对齐,展现出优秀的少量学习能力。BLIP2 [Li et al., 2023c] 提出了Q-Former,通过多个相关目标有效地对齐视觉编码器和LLM的特征。MiniGPT4 [Zhu et al., 2023; Chen et al., 2023a],mPLUGOwl [Ye et al., 2023a] 和 InstructBLIP [Dai et al., 2023] 使用Q-Former将仅限语言的指令调优扩展到多模态任务。LLaVA [Liu et al., 2023b,a] 通过线性投影层将视觉特征映射到LLaMA嵌入空间,同时与LLaMA [Touvron et al., 2023a] 进行微调。闭源的百度ERNIE 1和GPT-4V [OpenAI, 2023] 进一步展示了令人满意的图像理解能力。尽管现有MLLMs [Ding et al., 2021; Du et al., 2022; Zhang et al., 2023; Bai et al., 2023b; Chen et al., 2023b; Lin et al., 2023] 在常见多模态任务(如VQA [Antol et al., 2015] 和图像字幕生成 [Vinyals et al., 2015])中取得了令人印象深刻的成就,但它们的重点主要在于更广泛背景下的图像,忽视了专业领域中图表数据的理解。只有有限的研究 [Masry et al., 2022; Li and Tajbakhsh, 2023; Han et al., 2023] 关注了MLLMs的图表理解。
2.2 多模态基准测试
MLLMs已在众多传统基准测试上进行评估 [Goyal et al., 2017; Hudson and Manning, 2019; Xu et al., 2023; Ye et al., 2023b; Fu et al., 2023a; Yu et al., 2023; Li et al., 2023b; Liu et al., 2023c],这些测试通常覆盖通用世界数据,同时大大忽视了对复杂视觉图表理解和推理的需求。HallusionBench [Guan et al., 2023] 揭示了像GPT-4V [OpenAI, 2023] 和LLaVA-1.5 [Liu et al., 2023a] 这样的强大模型在面对复杂图表时易受到严重的视觉-语言(V-L)幻觉的影响。VisText [Tang et al., 2023] 引入了一个全面的基准测试,包括多级和细粒度的图表标注,涵盖图表构建、摘要统计、关系和复杂趋势等方面。然而,其图表种类有限。SciCap [Hsu et al., 2021]、Chart2Text [Kantharaj et al., 2022]、AutoChart [Zhu et al., 2021] 和ChartSumm [Rahman et al., 2023] 解决图表到文本总结任务。然而,这些方法要么依赖于需要昂贵手工标注的小型数据集,要么生成难以在实际场景中应用的刻板模板。ChartQA [Masry et al., 2022] 和PlotQA [Methani et al., 2020] 检验MLLMs的数字阅读能力,但它们的难度较低,因为MLLMs只需要OCR就能获得合适的候选答案。相比之下,我们的ChartBench提供了更多样化的图表和具有挑战性的问题,要求MLLMs彻底理解图表传达的视觉信息。
3 ChartBench
本节详细介绍了ChartBench。与现有的基准测试不同,ChartBench主要关注于感知能力和视觉逻辑推理能力。具体而言,我们强调评估在图表中未标注数据的值提取能力,而不是直接的OCR或定位问题。我们直接评估MLLMs的基本视觉推理能力,而不是将图表转换为文本描述并进行进一步的文本推理。
3.1 设计原则
ChartBench通过两个基本设计原则与现有基准测试区分开来。1) 更广泛的图表类型范围。ChartBench将ChartQA中的3种常见图表类型(线图、条形图和饼图)扩展到现实世界中的9种代表性图表类型(见图1&2a)。常规类别占54.8%,而新添加的类别占45.2%。ChartBench进一步将每个主要类别细分为多个子类别,使得MLLM性能的分析更加细致。2) 更直观的视觉逻辑。之前的基准测试只提供标注的图表,甚至包括元表数据作为输入提示,允许MLLMs仅基于文本逻辑推断出正确答案。相比之下,ChartBench包含更大比例的未标注图表(在图2b中占76.2%)。以图3中的图表为例。MLLMs需要依赖颜色或点形状来识别类别及其对应的坐标系统,并像人类一样准确地确定值,而不是仅依赖OCR进行提取。这一流程提供了对MLLMs在图表视觉推理能力的更现实的评估。
3.2 数据源与准备
为设计与现实世界密切相似的图表,我们从Kaggle收集了多组适合科学研究的主题和数据。为了确保数据隐私和安全,我们对所有真实姓名或其他可识别实体进行匿名处理。为了确保图表类型的多样性,我们仔细策划了各种数据格式,并主要依赖于专门为科学研究目的设计的在线绘图网站,使我们能够创建真实的图表。为了确保图表类型的多样性,我们利用ChatGPT [Radford et al., 2019] 生成虚拟但现实的主题和数据,并通过Matplotlib进一步增强图表多样性。随后,我们经过专家审查以消除缺陷样本(例如,标签遮挡)。这一过程产生了元数据和渲染的图表图像。
3.3 图表分类
先前的基准测试(例如,ChartQA [Masry et al., 2022])缺乏图表多样性,主要关注于条形图、线图和饼图。为了解决这一问题,ChartBench提供了共9个主要类别(见图2a分布)和42个子类别的图表,包括常规和专业图表。重要的是,ChartBench收集了大量未标注的图表。因此,MLLMs需要基于图表图例、轴对应关系和其他视觉提示进行视觉逻辑推理。
为了促进更全面的比较,我们为每个主要类别引入了带有标注数据的专用类别(见图2b分布),与ChartQA采取的方法保持一致。特别地,ChartBench主要关注于1) 常规图表,包括线图、条形图和饼图;2) 额外图表,包括散点图、雷达图、面积图、节点图、盒图和组合图表。请参考附录以获取详细描述和缩略图可视化。
3.4 自动化问答生成
特别地,ChartBench关注于MLLMs在两个类别的能力:感知和概念 [Fu et al., 2023a]。感知任务主要涉及感知和处理原始数据以提取有价值的特征和信息。相反,认知任务涉及处理和理解抽象概念和更高层次的信息。
感知任务主要包含两种类型的问答(QAs):1) 图表类型识别(CR, 图3 A)任务旨在评估MLLMs准确识别图表类型的能力。2) 值提取(VE, 图3 B)任务旨在评估MLLMs在面对复杂视觉逻辑时是否能正确提取相关值。在没有标注数据的情况下,MLLMs需要依靠图例、坐标轴和相应的图形元素来提供答案。
认知任务包括两种类型的问答(QAs):1) 值比较(VC, 图3 C)任务评估MLLMs的视觉推理能力,其中它们不需要识别图表的所有元数据。相反,它们仅依赖图形元素来确定比较答案。2) 全局概念(GC, 图3 D)任务评估从整体角度感知全局指标(如最大值)的能力。重要的是,MLLMs不需要识别所有图表元数据或元素布局。相反,仅通过观察图形元素和识别关键组成部分就足以得出准确结论。
3.5 评估指标
为了定量分析MLLMs的性能,我们探索了各种指令设计和评估指标。考虑到MLLMs对指令遵循的潜在变异性,我们采用了在MME [Fu et al., 2023a]中使用的是/否度量标准,这种度量标准从正面和负面两个角度提出问题。
改进的 Acc+。 考虑一个基本的查询 $Q_i$ 和图表 c,将 $Q_i$ 扩展到正确的 $Q_i^r$ 和错误的 $Q_i^w$ 判定,并给定查询提示。ChartBench 需要 MLLM $\mathcal{M}$ 来确定查询是否正确,并提供布尔输出 $A_i^r := \mathcal{M}(Q_i^r;c)$ 和 $A_i^w := \mathcal{M}(Q_i^w;c)$ 。由于简明的输出约束,不需要额外的语言模型来确定输出(如GPT得分)。相反,我们直接采用正则表达式匹配来确定模型的回复。注意:1)$Q_i^r$ 和 $Q_i^w$ 仅在GT值上有所不同,这导致它们具有类似的句子标记序列。2)获得 $A_i^r$ 和 $A_i^w$ 涉及两个独立的推理,而不是顺序的推理。3)$Q_i^w$ 中的非 GT 值是从元数据中随机选择的。基于这些定义,我们提出了改进的 Acc+ 指标。给定 ChartBench 中的 N 个基本查询,我们有
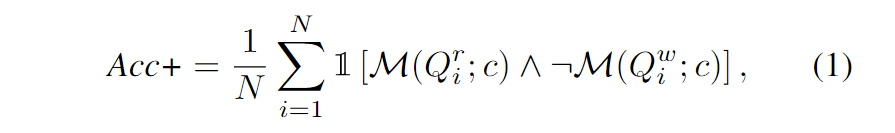
其中 ∧, ¬ 和 $\mathbb{1}(x)$ 分别表示逻辑与、非和指数函数。只有当 MLLM 同时准确回答了问题 $Q_i^r$ 和 $Q_i^w$ 时,才能确定其对查询图表的真正理解。
混淆率(CoR)。 基于Acc+,我们进一步提出了混淆率(CoR)指标来评估MLLMs未能理解图表的情况。给定一个图表和基本查询,积极 $Q_i^r$ 和消极 $Q_i^w$ 之间唯一的区别是GT真值的数值。因此,查询的文本特征非常相似,导致MLLMs如果未能理解图表c,则对于积极 $Q_i^r$ 和消极 $Q_i^w$都会提供相同的响应 $A := \mathcal{M(Q;c)}$ 。
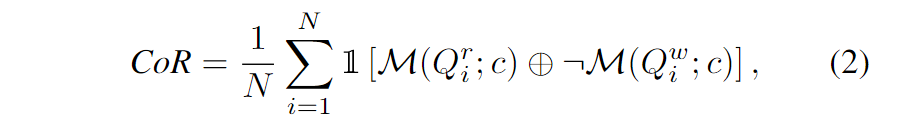
其中 ⊕ 是异或(XOR)操作符。通常,对于基本的 Acc+,随机猜测的预期概率为25%。然而,对于具有不足的图表识别能力的MLLM,混淆率(CoR)往往为100%,因此 Acc+ 的趋势是0%,而不是25%的基准线。
3.6 ChartCoT
如图4所示,我们基于思维链[Wei et al., 2022]提出了一个简单而有效的基线(ChartCoT),以增强视觉推理能力,而无需参数训练。具体而言,我们设计了一系列分解用户查询的问题,并采用提示来指导MLLMs模仿人类对图表识别的视觉推理。在没有表格数据或OCR可用的情况下非常有效。更直观的方法将是直接使用ChartBench数据进行指导调整。然而,这将导致数据泄露和在ChartBench上的不公平比较,如在ChartLlama [Han et al., 2023]和MVBench [Li et al., 2023d]中所观察到的。





