
PlotQA
PlotQA: Reasoning over Scientific Plots
PlotQA: 对科学图表进行推理
WACV 2020 | arXiv:1909
code:【传送门】
Abstract
现有的用于推理图表的合成数据集(如FigureQA、DVQA)缺乏数据标签的变化性、实值数据或复杂的推理问题。因此,针对这些数据集提出的模型并未完全解决推理图表的挑战。特别是,它们假设答案要么来自一个固定大小的小词汇表,要么来自图像中的一个边界框。然而,在实践中,这是一个不现实的假设,因为许多问题需要推理,因此其实值答案既不在固定大小的小词汇表中,也不在图像中。在这项工作中,我们旨在弥合现有数据集和实际图表之间的差距。具体来说,我们提出了PlotQA,它包含了来自真实世界来源的28.9百万个问题-答案对,涉及224,377个图表,以及基于众包问题模板的问题。此外,PlotQA中80.76%的超出词汇表(OOV)的问题具有不在固定词汇表中的答案。对PlotQA上的现有模型的分析表明,它们无法处理OOV问题:它们在我们的数据集上的整体准确率仅为个位数。鉴于这些模型并不是为这类问题而设计的,这并不奇怪。作为朝着一个更全面的模型迈出的一步,可以同时处理固定词汇表和OOV问题,我们提出了一种混合方法:特定问题的答案可以通过从固定词汇表中选择答案或从图表中预测的边界框中提取答案,而其他问题可以通过一个表问题回答引擎来回答,该引擎接收到从图像中检测到的视觉元素生成的结构化表格。在现有的DVQA数据集上,我们的模型的准确率达到了58%,明显提高了最高报告的准确率46%。在PlotQA上,我们的模型准确率达到了22.52%,明显优于现有的模型水平。
1. Introduction
数据图表,如条形图、折线图、散点图等,提供了一种有效的总结数值信息的方式。最近,在文献[13, 12]中提出了两个包含图表和用于对生成的图表进行问答的深度神经模型的数据集。在这两个数据集中,图表是通过合成生成的,其中数据值和标签来自一个自定义集合。在FigureQA数据集[13]中,所有问题都是二元的,答案要么是“是”,要么是“否”(见图1a中的示例)。DVQA数据集[12]将这一概念推广到包括可以通过以下方式回答的问题:(a)1000个单词的固定词汇表,或(b)从图表中提取文本(例如刻度标签)。例如,一个问题可能会寻求在条形图中特定标签的条的数值表示(见图1b)。鉴于DVQA数据集中的所有数据值都被选择为整数并来自一个固定范围,因此可以从适当的刻度标签中提取出这个问题的答案。
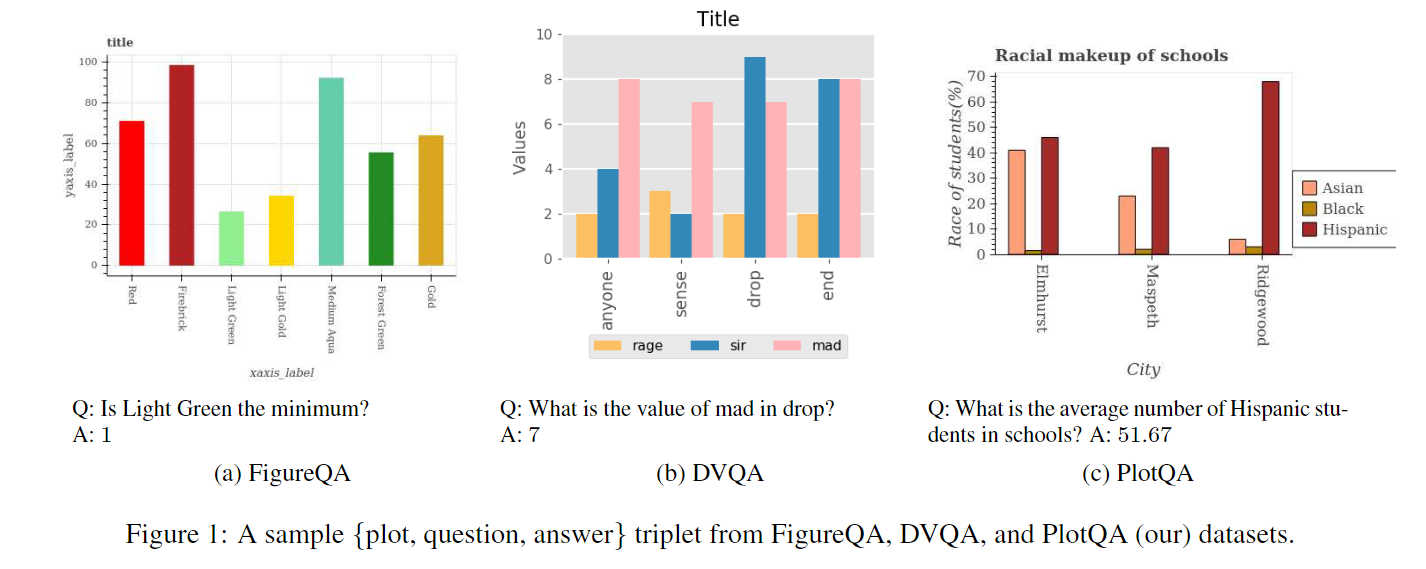
虽然这些数据集已经启动了对图表推理的研究问题,但图表上的实际问题要复杂得多。例如,考虑图1c中的问题,我们要计算由标签指定的颜色的三个条形的浮点数的平均值。这个问题的答案既不在固定词汇表中,也不能从图表本身中提取出来。回答这类问题需要结合感知、语言理解和推理,因此对现有系统提出了重大挑战。此外,如果训练集不是合成的,而是来源于具有浮点值大量变异性、轴和刻度标签多样性大以及问题模板自然复杂性的真实世界数据,那么这个任务将更加困难。
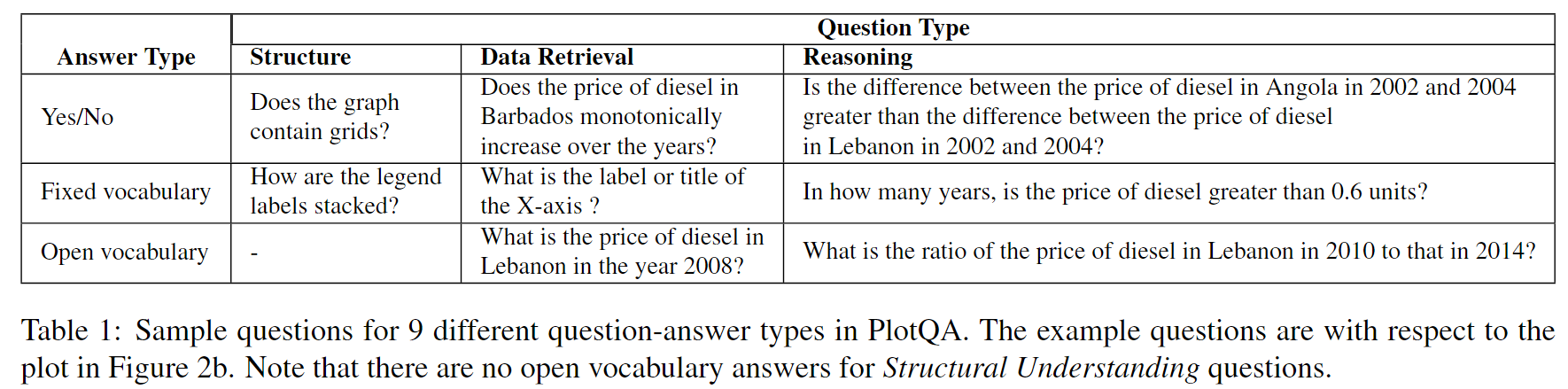
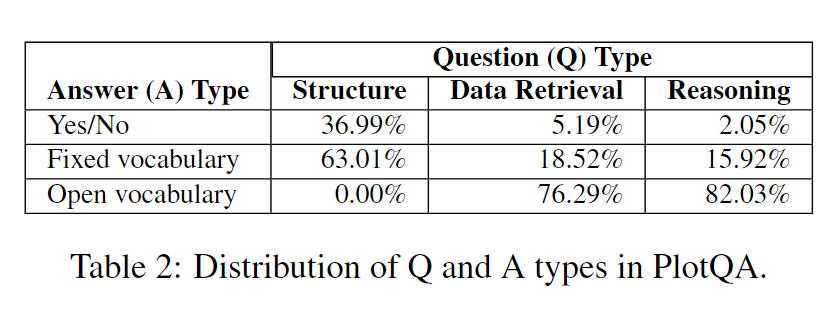
为了弥合现有数据集和真实世界图表之间的差距,我们引入了 PlotQA 数据集,其中包含了28.9百万个问题-答案对,关联了224,377个图表。PlotQA在三个方面改进了现有数据集。首先,大约80.76%的问题的答案既不在图表中,也不在固定词汇表中。其次,这些图表是从世界银行、政府网站等地方获取数据生成的,因此具有较大的轴和刻度标签词汇表,以及数据值范围广泛。第三,这些问题是复杂的,因为它们是基于从1,400个图表的样本集中提取的7,000个众包问答工作者提出的74个模板生成的。问题根据问题类型(‘结构理解’、‘数据检索’或’推理’)和答案类型(‘是/否’、‘固定词汇表’或’超出词汇表(OOV)’)分类为9(=3x3)个单元格(见表1)。
我们首先在PlotQA数据集上评估三种最先进的模型,即SAN-VQA[36]、Bilinear attention network (BAN)[16]和LoRRA[33]。需要注意的是,根据设计,这些模型都无法回答超出词汇表的问题。具体而言,SAN-VQA和BAN将图表推理视为一个分类任务,并期望答案位于一个小型词汇表中,而在我们的数据集中,答案词汇表过大(约5百万个词)。类似地,LoRRA假设答案本身作为文本出现在图像中,任务只是提取包含文本的区域,然后进行光学字符识别(OCR)。同样,这样的模型将无法回答图1c中所示的问题,而这类问题在现实世界的使用情况中占据了重要的部分,也是我们数据集的一部分。因此,这些模型在我们的数据集上的准确率不到8%。另一方面,现有模型(特别是SAN)在固定词汇表中的答案问题上表现良好,而这也是这些模型的预期目的。
基于以上观察,我们提出了一个混合模型,其中包含一个二元分类器,它在给定一个问题的情况下决定答案是否位于一个小的前k个词汇表中,或者答案是超出词汇表的。对于前者,问题通过一个分类管道传递,该管道预测出前k个词汇表上的一个分布,并选择最有可能的答案。对于后者(可以说是更难的问题),我们通过四个模块的管道传递问题:视觉元素检测、光学字符识别、提取到结构化表格中、以及结构化表格问答。这个提出的混合模型明显优于现有模型,并在PlotQA数据集上取得了22.52%的综合准确率。我们还在DVQA数据集上评估了我们的模型,在那里它的准确率为58%,改进了最佳报告结果SANDY[12]的46%。总之,我们提出了两个主要的贡献:
(1) 我们提出了PlotQA数据集,其中包含来自真实世界的数据的图表和基于手动筛选的问题模板的问题。该数据集揭示了需要训练模型来回答来自开放词汇表的问题的需求。
(2) 我们提出了一个混合模型,其中包含感知和问答模块,用于回答来自开放词汇表的问题。该模型不仅在我们的数据集上表现最好,而且在现有的DVQA数据集上也表现最好。
2. Related Work
在本节中,我们将讨论与我们的研究工作相关的几个方面的相关工作。这些方面包括图表理解、视觉问答和混合模型。
Datasets:
在过去几年中,已经发布了几个大规模的视觉问答数据集。这些数据集包括了针对自然图像提出的问题的数据集,如COCO-QA [28]、DAQUAR [23]、VQA [1, 7]等。另一方面,还有一些数据集,如CLEVR [11]和NVLR [35],其中包含基于合成图像的复杂推理问题,这些图像具有2D和3D几何对象。还有一些数据集 [14, 15] 包含了针对教科书中图表的问题,但这些数据集较小,并且包含多项选择题。FigureSeer [31] 是另一个数据集,其中包含从研究论文中提取的图像,但这也是一个相对较小的数据集(60,000张图像)。此外,FigureSeer侧重于回答基于线图的问题,而不是其他类型的图表,比如条形图、散点图等,如FigureQA [13] 和 DVQA [12] 中所见。最近还有TextVQA [33] 数据集,其中包含需要模型读取自然图像中的文本的问题。该数据集不包含需要数值推理的问题。此外,答案以文本形式包含在图像中。因此,目前没有任何现有数据集包含具有需要推理并且答案来自开放词汇表的复杂问题的图表图像。
上述提到的数据集的可用性促进了复杂的端到端神经网络模型的发展([36]、[22]、[37]、[25]、[30]、[12]、[33])。这些端到端网络包含以下组成部分:
(a) 编码器,用于计算图像和问题的表示,
(b) 注意力机制,用于聚焦问题和图像的重要部分,
© 交互组件,用于捕捉问题和图像之间的交互,
(d) 光学字符识别(OCR)模块,用于提取图像特定的文本,
(e) 一个分类层,用于从固定词汇表或附加了OCR的词汇表中选择答案。
3. The PlotQA dataset
在本节中,我们描述了PlotQA数据集及其构建过程。具体而言,我们讨论了四个主要阶段,即(i)筛选数据,例如按年份划分的降雨统计数据,按国家划分的死亡率等,(ii)创建不同类型的图表,包括元素数量、图例位置、字体等方面的变化,(iii)众包生成问题,以及(iv)从众包生成的问题中提取模板,并使用人工注释者建议的适当措辞来实例化这些模板。
3.1. Data Collection and Curation
我们考虑了诸如世界银行开放数据、政府开放数据、全球恐怖主义数据库等在线数据来源,这些数据包含了各种指标变量(如生育率、降雨量、煤炭产量等)跨年份、国家、地区等的统计数据。我们从这些来源中抓取数据,提取不同的变量,然后可以绘制它们之间的关系(例如,不同国家的年份对应的降雨量,或电影与预算之间的关系,或碳水化合物与食物项目之间的关系)。总共有841个独特的指标变量(如CO2排放、空气质量指数、生育率、收入等)和160个独特的实体(城市、州、地区、国家、电影、食物等)。数据的时间跨度从1960年到2016年,尽管并非所有指标变量在所有年份都有数据。数据包含正整数、浮点数、百分比和线性比例尺上的值。这些值范围从0到3.50e+15。
3.2. Plot Generation
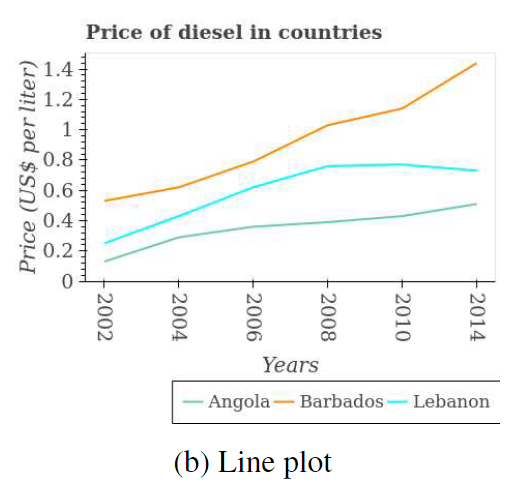
在这个数据集中,我们包含了3种不同类型的图表,即条形图、折线图和散点图。在条形图中,我们将它们按方向分为水平和垂直两种类型。图2显示了每种图表类型的一个样本。每种图表类型都可以紧凑地表示3维数据。例如,在图2b中,该图表比较了不同国家的柴油价格随着年份的变化情况。为了支持各种子任务的监督模块的开发,我们提供了图例框、图例名称、图例标记、轴标题、轴刻度、条形、折线和标题的边界框标注。通过使用不同的指标变量和实体组合(年份、国家等),我们共创建了224,377个图表。
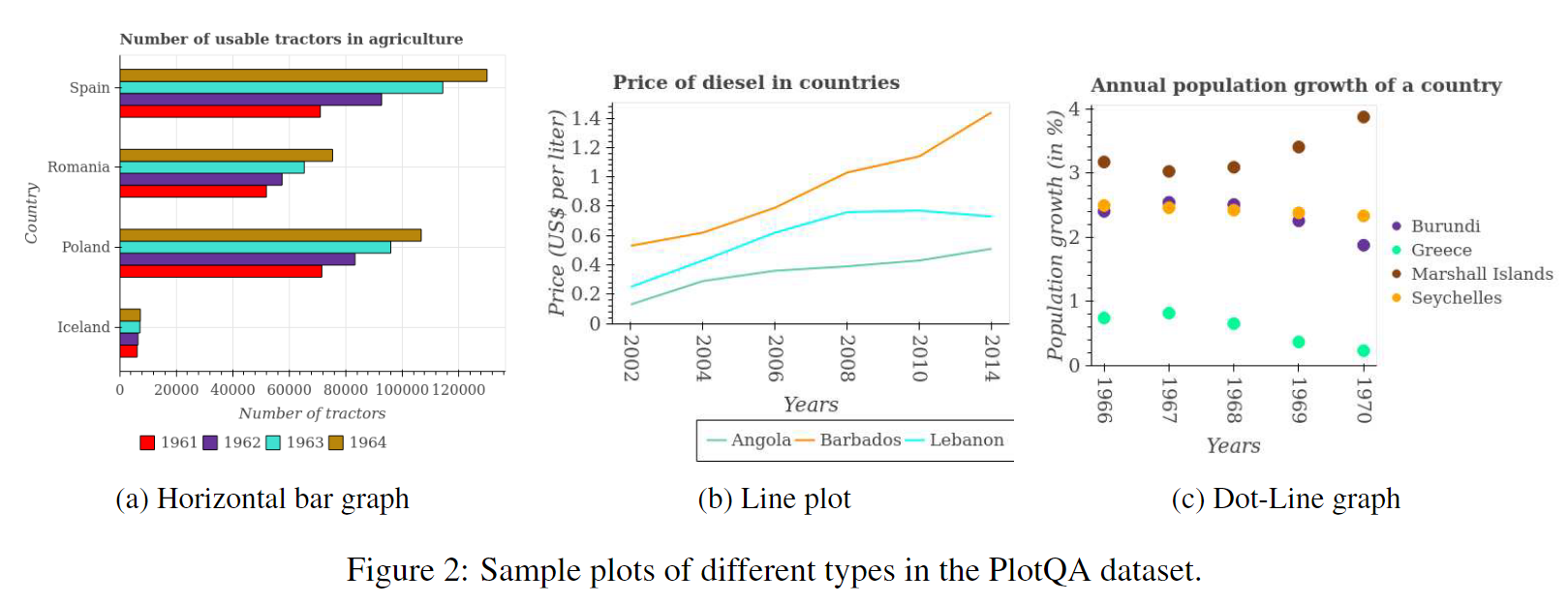
为了确保图表的多样性,我们随机选择了以下参数:网格线(存在/不存在)、字体大小、刻度标签使用的符号(科学-E表示法或标准表示法)、线型(实线、虚线、点线、短划线)、用于标记数据点的标记样式(星号、圆圈、菱形、正方形、三角形、倒三角形)、图例位置(左下、底部中心、右下、右中、右上)以及来自73种颜色中的线条和条形的颜色。x轴上的离散元素数量从2到12不等,图例框中的条目数量从1到4不等。
3.3. Sample Question Collection by Crowd-sourcing
由于PlotQA数据集的源数据相比于FigureQA和DVQA更加丰富,我们发现有必要邀请更多的注释者对这些图表生成问题。然而,为我们数据集中的所有图表创建问题将成本过高。我们从不同类型的图表中抽样了1,400个图表,并要求亚马逊机械土耳其(Amazon Mechanical Turk)上的工作者为这些图表创建问题。我们向每个图表展示给5个不同的工作者,总共得到了7,000个问题。我们明确指示工作者提出涉及图表中多个元素的复杂推理问题。我们支付给工作者每个问题0.1美元。
3.4. Question Template Extraction & Instantiation
我们手动分析了通过众包收集到的问题,并将它们分成了总共74个模板。这些模板分为3个问题类别。下面显示了这些问题类别以及一些示例模板。请参见表2以了解我们数据集中不同问题和答案类型的统计信息(更多详细信息请参阅补充材料)。
Structural Understanding:
结构理解:这些是关于图表整体结构的问题,不需要进行任何数量推理。例如:“有多少个条形图?”
**Data Retrieval: **
数据检索:这些问题寻求图表中单个元素的数据项。例如:“2015年缅甸纳税人的数量是多少?”
Reasoning:
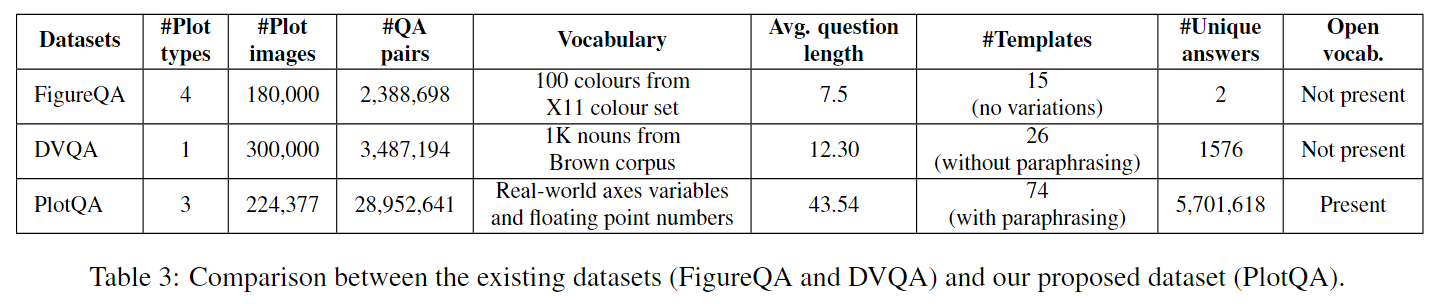
推理:这些问题要么需要对多个图表元素进行数字推理,要么需要对图表中不同元素进行比较分析,或者需要结合两者来回答问题。例如:“香蕉产量的中位数是多少?”我们将这些问题抽象为模板,例如“在多少个<X标签的复数形式>中,<图例标签>的<Y标签>是否大于所有<X标签的复数形式>中的平均<图例标签>的<Y标签>?”然后,我们可以通过用我们筛选的数据中的指标变量、年份、城市等替换X标签、Y标签、图例标签等来为每个模板生成多个问题。然而,这是一项繁琐的任务,需要大量的手动干预。例如,考虑图1c中的指标变量“学生种族”。如果我们直接将该指标变量替换到上述模板中,将得到一个问题:“在多少个城市中,亚洲学生的比例是否大于所有城市中亚洲学生的平均比例?”,这听起来不太自然。为了避免这种情况,我们要求内部注释者仔细地重新表述这些指标变量和问题模板。上述示例的重新表述版本是“在多少个城市中,亚洲学生的百分比是否大于所有城市中亚洲学生的平均百分比?”。通过这种半自动化的过程,我们生成了总共28,952,641个问题。**我们的这种基于精心筛选的问题模板在真实世界的图表数据上生成问题,然后进行手动重述的方法是我们工作的一个关键贡献。**由此产生的PlotQA数据集更接近于在图表上进行推理的真实挑战,显著改进了现有数据集。表3总结了PlotQA和现有数据集(FigureQA、DVQA)之间的区别。请注意:(a)PlotQA中唯一答案的数量非常大,(b)PlotQA中的问题要长得多,(c)PlotQA的词汇比FigureQA或DVQA更真实。
4. Proposed Model
目前用于视觉问答的现有模型主要有两种类型:(i)从图像中读取答案(如LoRRA)或(ii)从固定词汇表中选择答案(如SAN和BAN)。这样的模型对于DVQA等数据集效果很好,因为确实所有答案都来自固定词汇表(全局或特定于图表),但不适用于具有大量OOV问题的PlotQA。回答此类问题涉及各种子任务:(i)检测图表中的所有元素(条形图、图例名称、刻度标签等),(ii)读取这些元素的值,(iii)建立图表元素之间的关系,例如创建形式为 {country=Angola,year=2006,柴油价格=0.4 }的元组,以及(iv)对这些结构化数据进行推理。期望单个端到端模型能够完成所有这些任务是不合理的。因此,我们提出了一个多阶段管道来解决每个子任务。
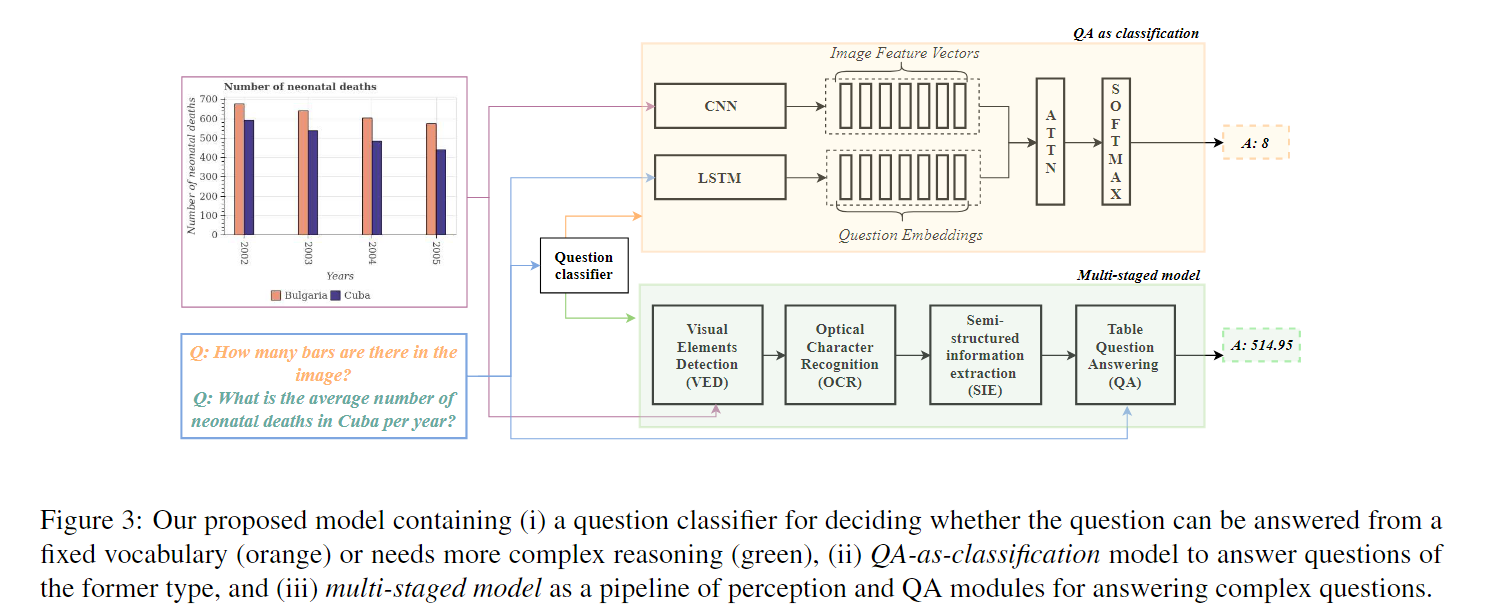
我们进一步指出,对于不需要推理并且可以根据一个小型固定大小的词汇表回答的简单问题,这样复杂的管道是不必要的。举个例子,考虑问题“图像中有多少个条形图?”这不需要推理,可以基于图像的视觉特性回答。对于这样的问题,我们有一个更简单的QA作为分类管道。如图3所示,我们的整体模型是一个混合模型,包含以下元素:(i) 一个二元分类器,用于决定给定的问题是否可以从一个小型固定词汇表中回答,或者需要更复杂的推理,以及(ii) 一个更简单的QA作为分类模型,用于回答前一类型的问题,以及(iii) 一个多阶段模型,包含下面描述的四个组件,用于处理复杂的推理问题。
4.1. Visual Elements Detection (VED)
图表中承载数据的元素可以分为10个不同的类别:标题、x轴和y轴的标签、x轴和y轴上的刻度标签(例如,国家)、图例框中的数据标记、图例名称,最后是图表中的条形图和折线图。根据现有文献([4]、[12]),我们将这些元素称为图表的视觉元素。第一个任务是通过在它们周围绘制边界框并将它们分类到适当的类别中来提取所有这些视觉元素。为此,我们可以应用物体检测模型,如Fast-RCNN [6]、YOLO [27]、SSD [21]、Mask-RCNN [9]等。在比较所有方法后,我们发现Faster R-CNN [29]模型以及Feature Pyramid Network(FPN)[20]的性能较佳。因此,我们选择了性能最佳的Faster R-CNN模型,并将其作为我们的视觉元素检测(VED)模块。
4.2. Object Character Recognition (OCR)
目标字符识别(OCR)。
一些视觉元素,如标题、图例、刻度标签等,包含数字和文本数据。为了从这些边界框内提取数据,我们使用了最先进的OCR模型[34]。我们将检测到的视觉元素裁剪到其边界框,将裁剪的文本图像转换为灰度,进行调整大小和去旋,并将其传递给OCR模块。现有的OCR模块在机器书写的英文文本方面表现良好,事实上,我们发现预训练的OCR模块在我们的数据集上表现良好。
4.3. Semi-Structured Information Extraction (SIE)
半结构化信息提取(SIE)
将数据提取到半结构化表格的下一个阶段将通过图3中的图表图像进行解释。SIE的期望输出是一个表格,其中行对应于x轴上的刻度标签(2002、2003、2004、2005),列对应于图例中列出的不同元素(保加利亚、古巴),第i行第j列的单元格包含与x轴的第i个刻度标签和图例的第j个对应的值。x刻度标签和图例名称的值可以从OCR模块中获得。图例名称到图例标记或颜色的映射是通过将图例名称与最接近的图例标记或颜色的边界框关联来完成的。类似地,我们将每个刻度标签与最接近刻度标签边界框的刻度标记关联起来。例如,我们将图例名称古巴关联到颜色“紫色”,将刻度标签2004关联到x轴上相应的刻度标记。通过这样做,我们得到了4行和2列的表头。为了填充表中的8个值,还有两个较小的步骤。首先,我们将8个条形图的8个边界框分别关联到它们对应的x刻度标签和图例名称。一个条形图与最接近其边界框的x刻度标签关联起来。为了将条形图与图例名称关联起来,我们在条形图的边界框中找到主要颜色,并将其与相应颜色的图例名称进行匹配。其次,为了找到每个条形图所代表的值,我们使用边界框信息提取条形图的高度,然后搜索该高度上方和下方的y刻度标签。然后,我们根据这些边界刻度的值进行插值,得到条形图的值。通过这样做,我们将图表中的信息提取到了一个半结构化的表格中。
4.4. Table Question Answering (QA)
管道的最后阶段是对半结构化表格进行问题回答。由于这类似于从WikiTableQuestions数据集[26]回答问题,我们采用了与[26]提出的相同方法。在这种方法中,表格被转换为知识图,并且问题通过应用组合语义解析转换为一组候选逻辑形式。然后,使用对数线性模型对这些逻辑形式进行排名,并将排名最高的逻辑形式应用于知识图以获得答案。需要注意的是,通过这种方法,输出是通过对数值数据操作的逻辑形式计算的。这支持复杂的推理问题,并且避免了在现有VQA工作中使用小型答案词汇进行多类别分类的限制。最近有关于在半结构化表格上回答问题的神经方法,例如[24, 8]。这些模型单独来看并没有超过相对简单的[26]模型,但作为一个集成,它们表现出了微小的改进(仅为1-2%)。据我们所知,只有一种神经方法[19]超过了[26],但是这种模型的代码不可用,这使得结果难以复现。
5. Experiments
在本节中,我们详细介绍数据拆分、基线模型、超参数调整和评估指标。
5.1. Train-Valid-Test Splits
通过使用841个指标变量和160个实体(年份、国家等)的不同组合,我们创建了总共224,377个图表。根据上下文和图表的类型,我们实例化了74个模板,为每个图表创建了有意义的{问题,答案}对。我们创建了训练(70%)、验证(15%)和测试(15%)的拆分(见表4)。数据集和众包问答可以从以下链接下载:bit.ly/PlotQA 。
5.2. Models Compared
-
IMG-only:这是一个简单的基线模型,我们只是将图像通过VGG19模型,并使用图像的嵌入来从固定词汇中预测答案。
-
QUES-only:这是一个简单的基线模型,我们只是将问题通过LSTM模型,并使用问题的嵌入来从固定词汇中预测答案。
-
SAN [36]:这是一个编码-解码模型,采用了多层堆叠注意力机制。它使用深度卷积神经网络为图像获取表示,并使用LSTM为查询获取表示。然后,它使用查询表示来定位图像中的相关区域,并使用这些区域来从固定词汇中选择答案。
-
SANDY [12]:这是DVQA数据集上性能最好的模型,是SAN的一个变体。不幸的是,该模型的代码不可用,并且论文中的描述不够详细,无法重新实现。因此,我们仅报告该模型在DVQA数据集上的结果(来自原始论文)。
-
LoRRA [33]:这是最近在TextVQA数据集上提出的模型。它将从预训练的ResNet-152模型提取的图像特征与从Faster-RCNN模型提取的基于区域的特征进行连接。然后,它使用预训练的OCR模块读取图像中的文本,并利用注意力机制对图像和文本进行推理。最后,它进行多类别分类,其中答案要么来自固定词汇,要么从图像中的文本中复制。
-
BAN [16]:该模型利用了两组输入通道之间的双线性交互,即每个问题词(GRU [3]特征)和每个图像区域(预训练的Faster-RCNN [29]对象特征)之间的交互。然后,它使用低秩双线性汇集[17]来提取每对通道的联合分布。BAN累积了8个这样的双线性注意力图,然后将其馈送到一个两层感知器分类器,以获得从固定词汇中的最终联合分布的答案。
-
我们的模型:这是图3中所示的提出的模型,具有两个模型路径。二元分类的训练数据是通过比较各个模型的性能来生成的:对于给定的问题,如果QA-as-classification模型的性能优于多阶段管道,则标签设置为1,否则设置为0。我们使用LSTM来表示输入问题,然后对该表示进行二元分类。
5.3. Training Details
SAN模型:我们使用了现有的SAN4实现进行最初的基线结果。图像特征从VGG19网络的最后池化层提取。问题特征是LSTM的最后隐藏状态。LSTM隐藏状态和每个位置的512维图像特征向量通过全连接层转换为1024维向量,然后加和通过非线性(tanh)函数。该模型使用Adam [18]进行训练,初始学习率为0.0003,批量大小为128,共进行25,000次迭代。
我们的模型:在提出的模型中,二元问题分类器包含一个50维的词嵌入层,后跟一个具有128个隐藏单元的LSTM。LSTM的输出投影到256维,然后馈送到输出层。该模型使用RMSProp进行10个epoch的训练,初始学习率为0.001。验证集的准确率为87.3%。多阶段管道的4个阶段中,只有两个需要训练,即Visual Elements Detection(VED)和Table Question Answering(QA)。如前所述,对于VED,我们使用PlotQA中的边界框注释训练了一个Faster R-CNN [20]的变体,其中使用了FPN。我们以批量大小为32进行了200,000步的训练。我们使用了初始学习率为0.004的RMSProp。对于Table QA,我们使用了我们数据集中的问题和相应的真实表格,训练了[26]中提出的模型。
5.4. Evaluation Metric
我们使用准确率作为评估指标。具体而言,对于文本答案(如India,CO2等),仅当预测的答案与真实答案完全匹配时,模型的输出才被视为正确。然而,对于具有浮点数值的数值答案,精确匹配是一个非常严格的度量标准。我们放宽了度量标准,认为答案是正确的,如果它与正确答案的差值在5%以内。
5.5. Human Accuracy on PlotQA dataset
为了评估PlotQA数据集的难度,我们报告了数据集测试集的一个小子集上的人类准确率。在内部注释员的帮助下,我们评估了160张图像上的5,860个问题。在这个子集上的人类准确率为80.47%。我们使用了第5.4节中定义的评估指标。大多数人类错误是由于数值精度,因为即使在5%的余量内,从图表中找到确切的值也是困难的。
6. Observations and Results
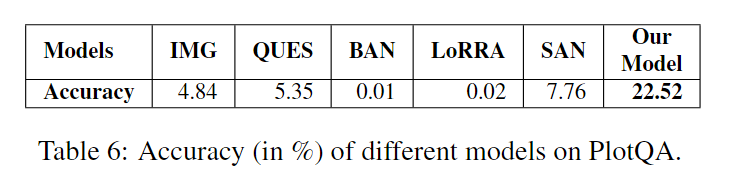
1. Evaluating models on PlotQA dataset (Table 6):
基线模型IMG-only和QUES-only的表现较差,准确率分别为4.84%和5.35%。现有模型(SAN、BAN、LoRRA)在该数据集上表现不佳。特别是,BAN和LoRRA的准确率低于1%,这并不令人意外,因为这两个模型都不是设计用来回答OOV问题的。此外,BAN最初提出的VQA任务并没有像PlotQA中发现的复杂的数值推理问题。类似地,LoRRA仅设计用于基于文本的答案,而不是需要数值推理的问题。请注意,我们使用了这些模型作者发布的原始代码。鉴于这些现有模型的特定重点和有限功能,甚至对我们的数据集进行评估可能显得不公平,但我们仍然这样做是为了完整性和突显需要更好模型的必要性。最后,我们的模型在PlotQA数据集上取得了最佳性能,准确率为22.52%。附录中包含了每种问题类型(结构化、数据检索、推理)和每种答案类型(二元、固定词汇、OOV)的性能细节。我们承认准确率明显低于人类表现。这表明数据集具有挑战性,并提出了关于视觉推理模型的开放性问题。
2. Analysis of the pipeline
我们分析了流水线中的VED、OCR和SIE模块的性能。
VED:
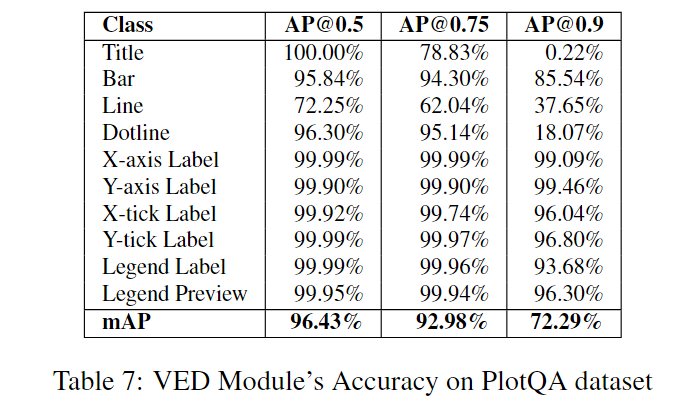
表7显示,VED模块在0.5的交并比(IOU)下表现相当不错。但是,在更高的IOU值0.75和0.9下,准确率急剧下降。例如,在0.9的IOU下,虚线的检测准确率不到20%。这揭示了这项任务与其他实例分割任务之间的有趣差异,在其他实例分割任务中,误差边界更高(接受0.5的IOU)。对于VQA任务来说,视觉元素检测的小错误(由75%的mAP得分表示)被认为是可以忽略不计的,但是对于PlotQA来说,小错误可能导致生成的表格严重偏离,进而影响了后续的QA准确性。我们通过图4中的示例来说明这一点。预测的红色框的IOU为0.58,估计的条形图大小为760,而实际情况是680,这严重影响了下游的QA准确性。
OCR:
OCR模块:我们评估OCR模块的独立/oracle模式和流水线模式。在oracle模式中,我们向OCR模型提供真实的边界框,而在流水线模式中,我们对VED模块的输出进行OCR。我们观察到从97.06%(oracle)下降到93.10%(经过VED后)的性能只有轻微的下降,这表明OCR模块对于在较高IOU下VED模块准确性的降低具有鲁棒性,因为它不依赖于类标签或边界框的确切位置。
SIE:
们现在评估SIE模块的性能。我们将表中的每个单元格视为一个元组,形式为{行标题,列标题,值}(例如,{波兰,1964年,10000台拖拉机})。我们考虑SIE模块提取的所有元组与地面实况表中的元组来计算F1分数。尽管表7表明VED模型的mAP@0.5非常准确,达到了96.43%,但我们观察到表格提取的F1分数仅为0.68。这表明许多值由于类似于图4中所示的错误而无法准确提取,其中边界框与真实边界框有很高的重叠。因此,我们需要更好的绘图VED模块,可以预测绘图的视觉和文本元素周围更紧密的边界框(在IOU为0.9时具有更高的mAP)。不准确的VED模块会生成错误的表格,进而影响下游的QA准确性。
总之,对于结构化图像来说,高度准确的VED仍然是一个开放性挑战,可以提高对绘图的推理能力。
3. Evaluating new models on the existing DVQA dataset(Table 5):
所提出的模型表现优于现有模型(SAN 和 SANDY-OCR),在 DVQA 上建立了新的 SOTA 结果。与 PlotQA 结果相比,所提出的混合模型表现更好,这表明在 DVQA 数据集上提取的结构化表格更准确。这是因为轴和刻度标签的变化有限,标签长度较短(仅一个词)。
7. Conclusion
我们引入了 PlotQA 数据集,以缩小现有合成图表数据集和真实世界图表及问题模板之间的差距。对 PlotQA 上现有的 VQA 模型的分析表明,它们在处理开放词汇问题时表现不佳。这并不奇怪,因为这些模型并非设计用于处理需要数字推理和 OOV 答案的复杂问题。我们提出了一个混合模型,用于处理(i)可以从固定词汇回答的较简单问题和(ii)包含 OOV 答案的较复杂问题。对于 OOV 问题,我们提出了一个流水线方法,结合了可视元素检测和 OCR 与表格上的 QA。所提出的模型在 DVQA 和 PlotQA 数据集上都取得了最新的结果。对我们的流水线的进一步分析揭示了需要更准确的可视元素检测来改善对图表的推理。




