ChartReader
ChartReader: A Unified Framework for Chart Derendering and Comprehension without Heuristic Rules
ChartReader:无启发式规则的图表解渲染与解释的统一框架。
arvix2304
code: 【传送门】
0. Abstract
图表是可视化转换复杂数据的一种有力工具,但是由于图表有丰富的类型和组件,所以图表理解面临着很大的挑战。现存的图表理解方法面临着以下两个问题:①要么利用启发式的规则,②要么过度依赖于 OCR 系统,导致了次优性能。为了解决这些问题,作者提出了 ChartReader ,一个结合了图表解渲染和理解任务的统一框架。本文的方法包含了一个基于 transfomer 的图表组件检测模块和一个面向 chart-to-X 任务的额外的视觉-语言预训练模型。通过自动的从带标注的数据集中学习图表的规则,本文的方法消除了对人工制定规则的需要,降低了这部分的工作量并提升了准确度。本文还为交叉任务训练引入了一种数据变量替代机制以及对于预训练模型的输入和位置 embeddings 的扩展。作者评估了 ChartReader 在 Chart-to-Table,ChartQA,和 Chart-to-Text 任务上的表现,并证实了该方法相比现有方法的优越性。我们提出的框架可以显著减少图表分析中的手动工作,为实现通用图表理解模型迈出了一步。此外,我们的方法为与主流的大型语言模型(LLMs)如T5和TaPas的即插即用集成提供了机会,拓展了它们在图表理解任务中的能力。
知识补充
OCR:
OCR 是“Optical Character Recognition”的缩写,中文翻译为“光学字符识别”或“光学文本识别”。OCR 是一种技术,它使用计算机视觉和模式识别技术来将图像中的文本转换为可编辑的文本数据。这项技术的主要目的是使计算机能够理解和处理图像中的文字,就像处理其他文本数据一样。
OCR 系统通常包括以下步骤:
- 扫描或获取图像: 通过扫描仪、相机或其他设备获取包含文字的图像。
- 预处理: 对图像进行一些预处理步骤,如去除噪音、调整图像的对比度和亮度等。
- 分割: 将图像中的文本分割成单个字符或单词。
- 识别: 对分割后的字符或单词进行光学字符识别,将其转换为计算机可识别的文本数据。
- 后处理: 对识别结果进行进一步处理,提高准确性,可能包括拼写检查和格式化。
OCR 技术在许多领域都有广泛的应用,例如文档数字化、自动化数据输入、图书馆数字化项目、手写文字识别等。
conclusion
本文提出了一个 ChartReader 的统一框架,将图表去渲染和理解任务很好的结合在一起。该方法利用了基于 Transformer 的图表组件检测模块和一个扩展的 vision-language 预训练模型来进行图表理解任务,并提高了准确度。通过扩展实验,证实了 ChartReader 在 Chart-to-Table, ChartQA, Chart-to-Text 等任务上比现有方法表现更好。
本文提出的框架有希望大幅减少在图表分析中的人工投入,并向通用的图表理解模型的迈进。
1. INTRODUCTION
Chart derendering (图表解渲染)就是将图表转换为表格(即 Chart-to-Table)。

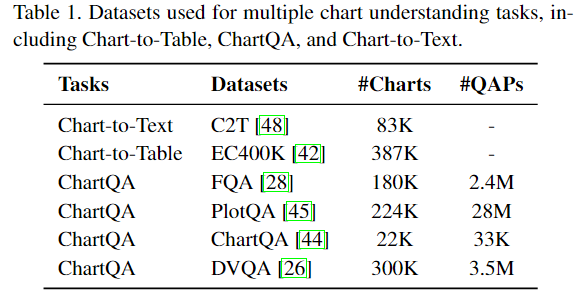
目前分别解决 Chart-to-Table, ChartQA, Chart-to-Text 这三个任务(如上图1)尚且没有很好的方法,更不要说提出一个统一的解决方法了。
如下图2,图表有各种各样的类型,分别设计用来传达不同领域的的知识,展示出复杂的组成成分,纹理变化和斑点背景。面对负责的图表,现存的图表理解方法面临着两个主要问题:
-
现有的图表去渲染方法(即 Chart-to-Table)需要借助于广泛的领域知识和辛苦制定的启发式规则。
例如 ChartOCR ,一种开创性的方法,需要先利用图表分类识别类别,然后使用不同的预定义的启发式规则检测不同的组件。为了避免复杂的规则制定,一些方法甚至尝试仅使用一组有限的图表种类,例如条形图和折线图。
这些限制阻碍了对未知类别数据的提取能力。现有的一些方法甚至直接使用 GT 的表格来完成回答和总结任务。这证实了自动化和从真实图表中提取数据是具有挑战的。
-
当前的图表理解方法,例如 Chart-to-Text 和 ChartQA 通常严重依赖于现成的 OCR 系统或者从 GT 预提取的表。
通过将图表去渲染视为一个黑盒,这些方法忽视了图表的视觉和结构信息,导致了如下的两个问题:
1)Chart-to-Text 和 ChartQA 任务演变为纯文本测试,因为不能提取图表解渲染的视觉语义。这解释了为什么基于 OCR 和端到端的方法,例如 LayoutLM, PresSTU, PaLI, CoCa, Donut, 和 Dessurt 在图表理解上表现出次优结果。
2)Chart-to-Table 任务没能从图表理解任务中获利,由于缺乏对于图表的视觉语义的理解。现存的系统,例如使用 OCR 的系统难以实现高精度的将图表转化为表格。
综上,作者认为图表理解的任务来源于过度依赖预定义的规则和缺乏支持多任务的通用框架。
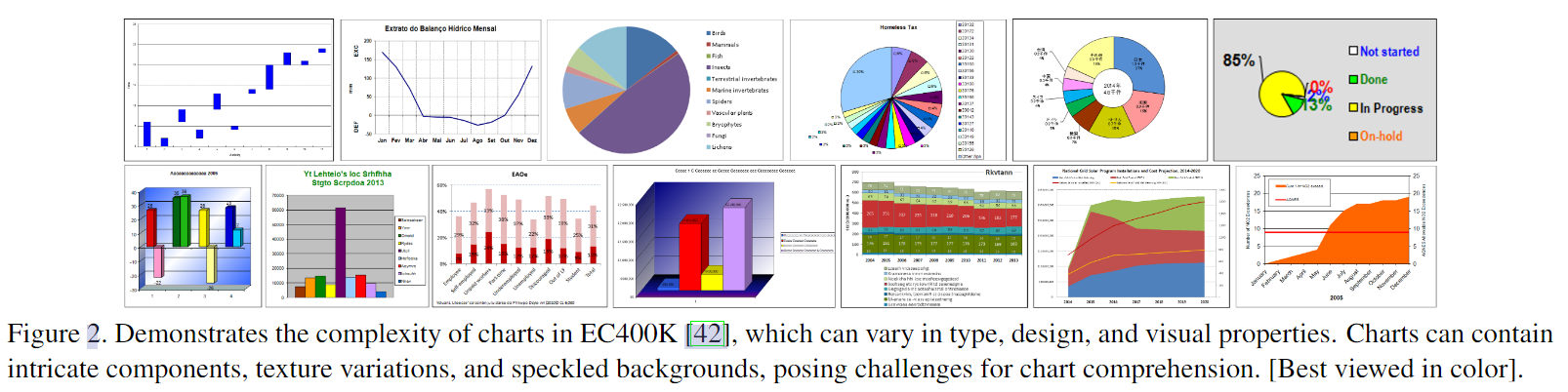
鉴于前面的分析,使用 vision-language 模型可能是构建通用框架的方向。Pix2Struct 是一种视觉定位语言的预训练策略,比基于 OCR 的模型性能表现更好,但是不适合做图表去渲染。但是由于缺乏更好的 vision-language 模型,Metcha(Enhancing Vision Language Pretraining with Math Reasoning and Chart Derendering) 不得不利用 Pix2Struct 作为 backbone。然而 Metcha 和 Pix2Struct 都没有解决前面提到的两个问题:
1)图表解渲染过度依赖于启发式规则;
2)尽管尝试合并额外的图表理解任务,但是严重依赖于现有的 OCR 系统。
为了克服上述问题,作者引入了 ChartReader,一个统一框架将 chart derendering 和 comprehension tasks 无缝结合。该方法由一个无规则的图表组件检测模块和一个面向 chart-to-X 的视觉-语言预训练模型组成。与基于启发式规则的方法不同,该方法利用基于 transformer 的方法来检测图表组件的位置和类型,通过处理现有的有标注数据集来自动化的学习规则。为了增强交叉任务的训练,作者扩展了预训练模型的输入和位置的 embedding ,并引入了数据变量的替换技术。特别的,作者将 chart-to-X(table/text)任务规范化为 question-answering 问题,允许高效实现多个图表理解任务。此外模型生成数据变量而不是真实值以避免错误和幻觉,这提升了多任务训练的一致性。该方法向图表理解的统一模型迈进了一步。
幻觉:简单说就是对一些内容的误解。
本文作者主要的贡献是:
- 提出一个统一的框架,将图表解渲染和理解任务无缝结合;
- 一个基于 transformer 的无规则图表组件检测模块,以自动化的学习图表规则;
- 扩展预训练模型 LLMs 中的输入和位置 embeddings,并且使用了一种数据变量替代方法来提升交叉任务的训练;
- 通过实验验证了本文方法,证实了本文方法比现存的方法在图表理解任务上有了大幅提升。
2. Related Works
Chart Derendering
即 Chart-to-Table ,涉及对图像图表组成组件的识别,例如柱形,饼,和图例,以提取图表中的潜在的数据。
- 传统的方法依赖于基于边缘和颜色的手动设计的规则,这将耗费大量的时间而且不容易泛化到新的图表类型上。
- 基于深度学习的方法使用目标检测和文本识别网络可以准确地检测图表成分,具有更好的泛化性。
但是近期的一些工作企图使用预训练的大语言模型(LLMs)做 plot-to-table 任务,无需识别图表的组件。 flagship 方法,ChartOCR 等虽然取得了一些进展,但对于每一种图表类型依然严重依赖人工制定的规则和不同的网络。相反,本文的方法消除了对启发式规则的需要,可以更容易地扩展到没见过的图表类型。
Chart Question-Answering
通过视觉和文本信息回答图表相关的问题。早期的方法依赖于关系网络来表示图像对象之间、或视觉和问题之间的关系,而引入了动态编码来处理词汇表之外的候选答案。
后来的方法利用了多模态模型(使用 LSTM 和 DenseNet 来提取视觉和文本特征)和融合嵌入(fuse embeddings)来回答问题。
最近的方法,比如 OpenCQA, CRCT, ChartQA, PlotQA-M, 和 STL-CQA 结合了 Transformers 在回答问题时捕捉复杂的视觉和文本信息。此外,一些方法企图使用预训练的 LLMs 用于图表和语言数据的建模,但是它们总是忽略图表特征仅仅依赖于真实图表。相比之下,本文的工作将图表摘要和解渲染任务融入图标问答任务,使用单个 sequence-to-sequence 框架优雅的将不同任务的图表特征和有意义的方面结合到 LLMs 中。
Chart Summarization
指 Chart-to-Text ,目标是从视觉图表中生成自然语言摘要。
- 传统方法使用模板对图表特征提供简要的描述;
- 还有一些其他方法使用启发式或基于规划的方法来创建多媒体演示;
最近,基于启发式规则的自然语言生成技术已经被应用,包括统计分析来推断洞察力,以及编码器-解码器结构来生成基于模板的标题。但是这些方法有一个共有的限制:它们依赖于预定义的基于模板的方法,这使其可能缺乏语法风格与词法选择的普遍性和变化。
本文的方法提出了一种通用的基于数据驱动的 sequence-to-sequence 图表理解框架来生成更多样化、信息丰富的摘要。
Advancements in Vision-Language Research
近期视觉语言研究主要集中在自然图像上面,依赖于基于视觉的推理和合成数据集来进行评估。但是这些方法没有捕捉到真实世界视觉语言的复杂性,尤其是在图表理解任务上。
基于 OCR 和端到端的一些方法,没有具体的解决图表理解带来的挑战。尽管编码器-解码器框架已经被广泛的应用,它仍然需要考虑针对性的设计,例如确定哪些输入是有价值的, 以及消除人为规则。没有这些模块,现有的模型,例如 LaTr, GIT 等将不能直接应用在图表理解任务上。
本文的工作消除了这些限制,不需要预定义启发式规则, 并统一化了编码器-解码器架构中的数据提取和理解,实现了不错的结果。
3. Unified ChartReader Framework
统一框架的目标是支持各种图表分析任务,包括 chart-to-table, chart-to-text, 和 chartQA。如图3所示,这包含了两个主要组件:
- 一个无规则的图表组件检测模块;
- 一个用于 chart-to-X 的扩展的预训练视觉语言模型。
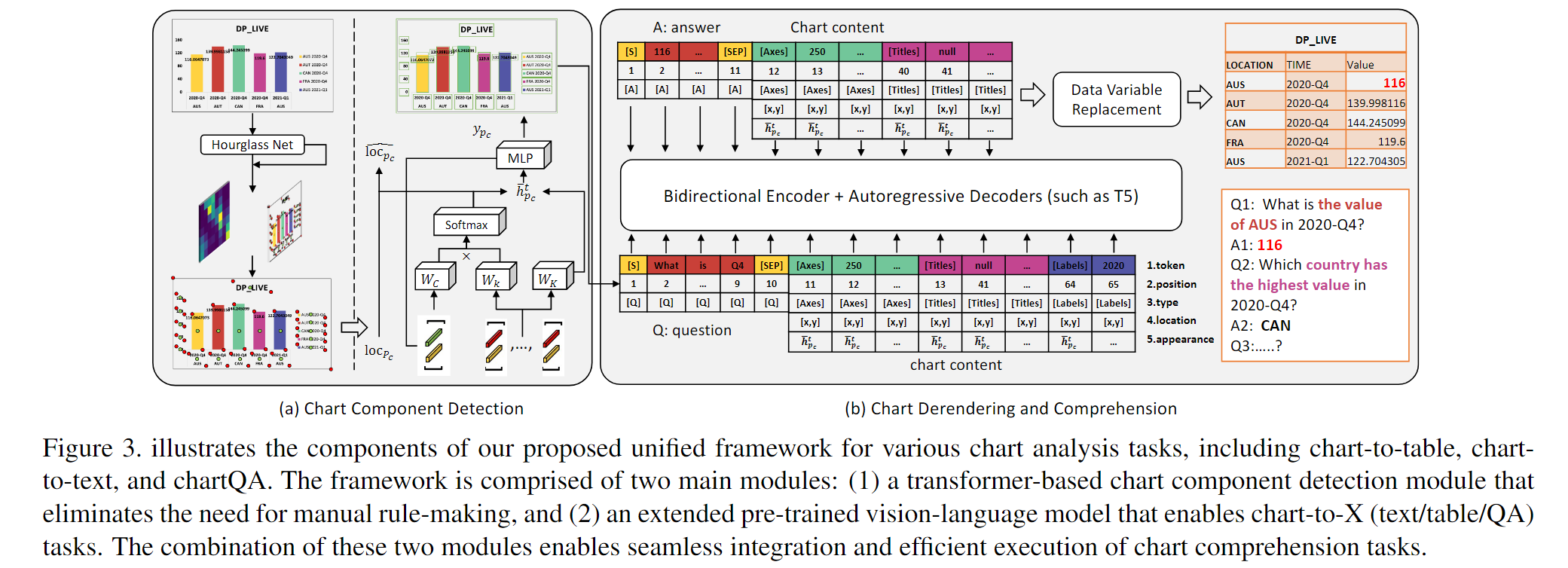
3.1 Chart Component Detection
本文利用基于 transformer 的方法来检测图表组件的位置和类型,不利用启发式规则。该方法由三种主要步骤组成:
- center/keypoint detection
- center/keypoint grouping
- component position/type prediction
Overcoming Heuristics
背后的动机是要克服基于启发式规则的方法在处理严重依赖于领域知识和复杂规则定义的各种图表样式时的局限性。通过处理有标签的现存数据集,本文的模型可以自动学习图表的规则。优化后的框架可以无缝应用于其他下游的图表理解任务。
如图4所示,本文的更新模型依赖于从现有数据集中推断出的中心和关键点,以替代启发式规则来定位图表组件并克服图表风格变化带来的影响。作者将每个图表组件的左上角、右下角和中心分别转换为中心点和关键点。尽管该方法仍然需要大量的带标记数据,但是不需要对每种图表类型设计特定的规则。通过实验证实,该方法是向统一的图表理解模型迈进的一步。
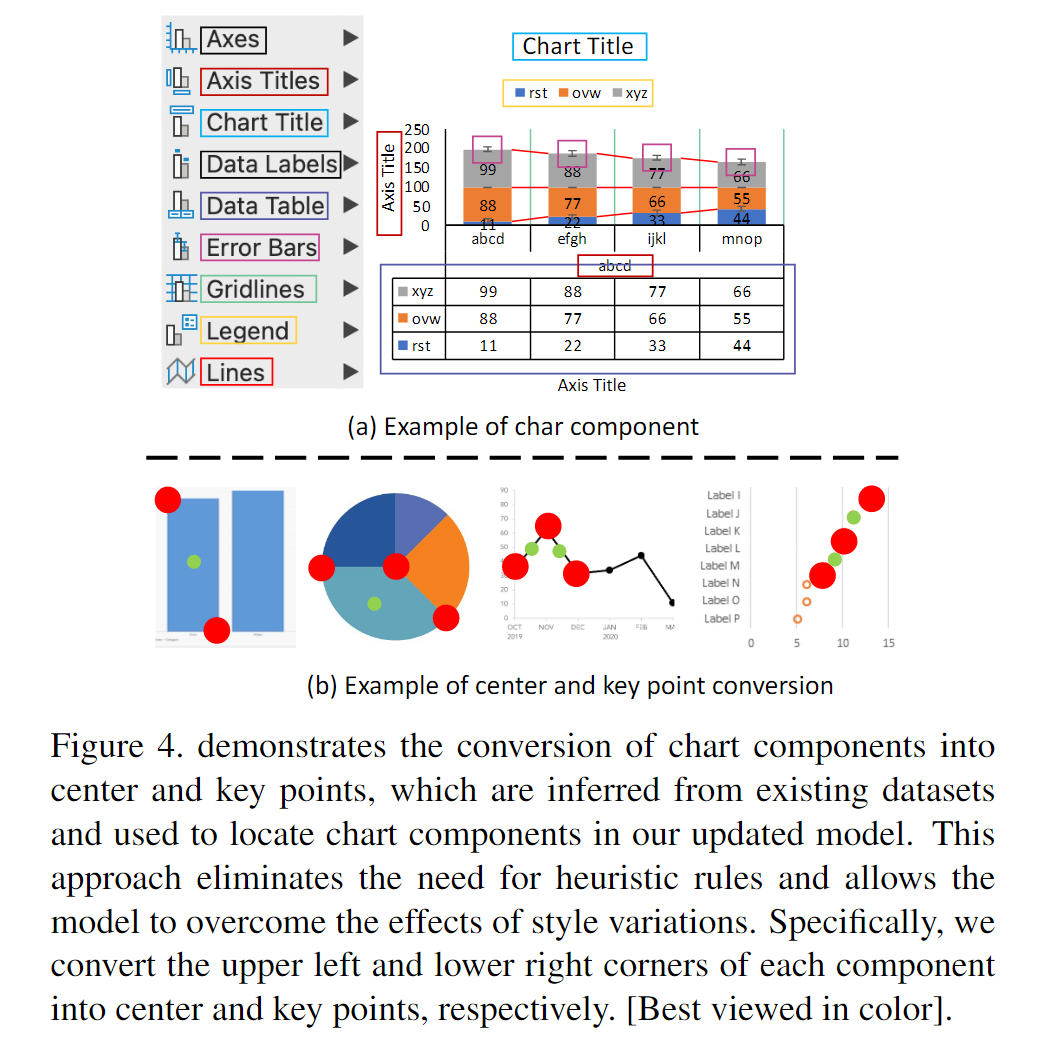
Step-1: Center/Keypoint Detection
作者使用没有 the corner pooling layer 的 Hourglass network 来检测图表组件的中心 $p_c \in \mathcal{C}$ 和关键点 $p_k \in \mathcal{K}$ 以提升图表样式的通用性。中心 $\widehat{\operatorname{loc}}_p \in \mathbb{R}^2$ 和组件类型 $\hat{y}p \in {1, \dots, \mathcal{T}}$ 对于所有中心和关键点使用 focal loss $L{focal}$ 和平滑 $L_1$ loss。作者对所有组件类型使用中心池化层,以有效检测不同类型的图表组件的中心和关键点。
Step-2: Center/Keypoint Grouping
对于每个检测到的中心和关键点,我们提取了它们相关位置的特征以获取初始的 embeddings。为了更好的确定图表组件,引入了一类 token $\phi_{p_c}$ 和 $\phi_{p_k}$ 并使用多头注意力来获取中心点 $p_c$ 和关键点 $p_k$ 的权重,
$$
\mathcal{G}(p_c, p_k) = (\mathbf{W}{\mathcal{C}} [h{p_c}, \phi_{p_c}])^T \mathbf{W}{\mathcal{K}} [h{p_k}, \phi_{p_k}], \tag{1}
$$
$h_{p_c}$ 和 $h_{p_k}$ 分别表示中心点和关键点的隐藏特征。$\mathbf{W}{\mathcal{C}}$ 和 $\mathbf{W}{\mathcal{K}}$ 是中心点和关键点隐藏特征的传播矩阵。作者使用固定的正弦特征对 x 轴和 y 轴的绝对位置编码,并在乘法之前将 $\phi_{p_c}$ 和 $\phi_{p_k}$ 添加进 embedding 中。
在通过方程 1 获取权重 $\mathcal{G}$ 之后,在整个关键点集合上使用 softmax 函数进行权重归一化来计算最终的分组分数,
$$
\operatorname{attn}(p_c, p_k) = \frac{\exp (\mathcal{G}(p_c, p_k))}{\sum_{\bar{k} \in \mathcal{K}} \exp(\mathcal{G}(p_c, p_{\bar{k}}))}, \tag{2}
$$
其中 softmax 函数对相同组件中的关键点 $\bar{k} \in \mathcal{K}$ 进行排序,并过滤掉每个中心点 $p_c$ 中最相关的一个(即 $p_k$)。该方法能够高效的将中心点和关键点分组到对应的图表组件中。
Step-3: Component Position & Type Prediction
作者通过使用 Hourglass 网络中的分组分数和关键点位置来优化中心点位置,以预测图表组件的位置和类型。
为每个中心点 $p_c$ 计算关键点位置 $\widehat{loc}{p_k}$ 的权重均值,使用的分组分数如下,
$$
\widehat{loc}{p_c} = \sum_{k \in \mathcal{K}} \operatorname{attn}(p_c, p_k) \widehat{loc}{p_k}. \tag{3}
$$
为确保预测位置接近真实位置 $loc{p_c}$ ,使用 location loss $L_{loc}$ ,定义如下,
$$
L_{loc} = \sum_{c \in \mathcal{C}} |\widehat{loc}{p_c} - loc{p_c}|. \tag{4}
$$
为了预测图表组件的类型,计算关键点 embeddings 的权重之和,使用的分组分数计算如下,
$$
\bar{h}{p_c} = \sum{k \in \mathcal{K}}attn(p_c, p_k) \mathbf{W}{\mathcal{K}} [h{p_k}, \phi_{p_k}]. \tag{5}
$$
得到的中心点 embedding $\bar{h}{p_c}$ 随后被传递给 MLP 层以获取所有组件类型的预测概率分布,然后使用交叉熵 loss $L{CLS}$ 与真实组件类型标签 $y_{p_c}$ 进行比较,
$$
L_{CLS} = -\sum_{c \in \mathcal{C}} y_{p_c} log(softmax(\bar{h}_{p_c})). \tag{6}
$$
3.2 Chart Derendering and Comprehension
作者提出了一个统一的图表理解框架,把 Chart-to-X(text/table/QA) 任务按照 chartQA 任务来处理。
为了提升跨任务训练,作者扩展了1)预训练模型的输入和位置 embeddings 2)使用了数据变量替换机制。
Motivation & Reasoning
本文的方法受到如下两个原因的启发:
- 把 chart-to-X(table/text) 作为 问答 问题处理;
- chart-to-table 将轴坐标和图例的组合构成问题,将提取的组件用作答案;
- chart-to-text 当成 QA 问题来处理,以填充去除冗余信息后带来的空白模板。
- 这些任务的最新进展使用了 sequence-to-sequence 模型。为了在一个框架下解决这些任务,作者将预训练的 LLMs 扩展到各种图表理解任务上。
- 采用了大量实验确定了怎样扩展输入和位置编码;
- 提出了一种数据变量替换机制来提升多任务训练的一致性;
本文的研究为扩展预训练的 LLMs 到图表理解提供了可能,可以无缝的扩展到主流的 LLMs 如 T5 和 TaPas。
Positional & Input Embedding
为了支持各种图表理解任务,要将输入和位置 embeddings 从自然语言扩展到图表风格的数据。将 embedding $z_k$ 融合进序列的第 k 个位置的定义如下,
$$
z_k = \operatorname{LN}(z_k^{pos} + (z_k^{token} + z_k^{typ} + z_k^{loc} + z_k^{app})), \tag{7}
$$
$LN()$ 表示归一化层。
首先,位置 embedding $z_k^{pos}$ 置为 0,因为现代视觉-语言预训练模型使用相对位置嵌入。
其次,输入 embedding 包含了图表组件的 type,location,appearance,以及从数据集中的其他文本信息中获取的 token。
$z_k^{token}$ 是通过标记文本单词的串联来生成的,定义如下,
$$
x^{token} = \left{\begin{array}{l}
[S], [w_1], \dots, [w_m], [SEP], [y_{pc}^1, w_{1,1}] \
, \dots, w_{1, m}, [y_{pc}^N], w_{r_N}, 1, \dots, w_{r_N}, m, \dots, .
\end{array}\right},
$$
[S] 用于区分问题和答案,[SEP] 表示图表上下文的存在。为了合并图表组件的有关信息,引入了一个特殊的 token $[y_{pc}^i]$ 来表示图表组件的类型 $y_{pc}^i \in {1, \dots, \mathcal{T}}$ (例如, [Axes]) 。从每个图表组件获取的文本 tokens 表示为 ${w_{1,1}, \dots, w_{1, m}}$ 。
为了捕获图表的语义信息,作者为图表组件类型组合了一个可学习的独热 embedding $z_k^{type}$ 。图表的第 k 个 token 的位置表示为 $x_k^{loc}$ ,是一个基于相对边界框坐标(relative bounding box coordinates)的 4 维特征,如下,
$$
x_k^{\mathrm{loc}}=\left(x_k^{\min } / W_{\mathrm{im}}, y_k^{\min } / H_{\mathrm{im}}, x_k^{\max } / W_{\mathrm{im}}, y_k^{\max } / H_{\mathrm{im}}\right) \text {, }
$$
其中 $\left(x_k^{\min }, y_k^{\min }\right)$ 和 $\left(x_k^{\max }, y_k^{\max }\right)$ 表示第 k 个 token 的边界框的左上角和右下角,而 $W_{\mathrm{im}}$ and $H_{\mathrm{im}}$ 分别表示图表的宽度和高度。为了将每一个图表组件的外观纳入考虑,作者将中心和相应关键点的特征连接起来以获取最终的 appearance embedding $z_k^{\text {app}}$ 。
Data Variable Replacement Technique
通过结合数据变量替换技术来增强训练过程。在训练过程中,模型生成了相关的数据变量来替代真实值,避免了将数据记录视为 regular token 而带来的错误或幻觉。例如,表格单元中的数值被替换为 “product1”,“product2” 等数据变量。这种方法提高了生成摘要、表格、答案时的准确性和事实一致性,尤其是当多个数据记录参与时。
为了监督数据变量的使用,引入了一个新的损失项来惩罚模型生成与任何数据变量不匹配的 token。该 loss 项使用函数 $D(x)$ 返回与 token x 匹配的数据变量,如果存在,则全部返回,否则返回 null。这个 loss 项的定义如下,
$$
L_{var} = - \frac{1}{T} \sum_t^T \sum_i^{N_i} \sum_{j \in V} I_{D(x_i)} = v_j log P_{i, j}(t), \tag{8}
$$
T 是生成的输出的长度,$N_t$ 表示第 t 个输出的 token 数量,$P_{i, j}(t)$ 是在第 t 个时间步,生成第 i 个 token 作为第 j 个数据变量的概率。$I_{D(x_i)} = v_j$ 是一个指标函数,如果 $D(x_i) = v_j$ 等于 1,其他情况等于 0。
最终的优化是优化两个 loss 的和,$\alpha$ 是一个超参数用于平衡两个 loss,
$$
L = L_{ans} + \alpha L_{var}, \tag{9}
$$
$L_{ans}$ 会根据特定的图表理解任务微调。
总之,使用数据变量替换的方法可以同时支持 chart-to-text, chart-to-table, 和 chartQA 任务。
引入的 loss 项可以确保在训练过程中正确的使用数据变量。
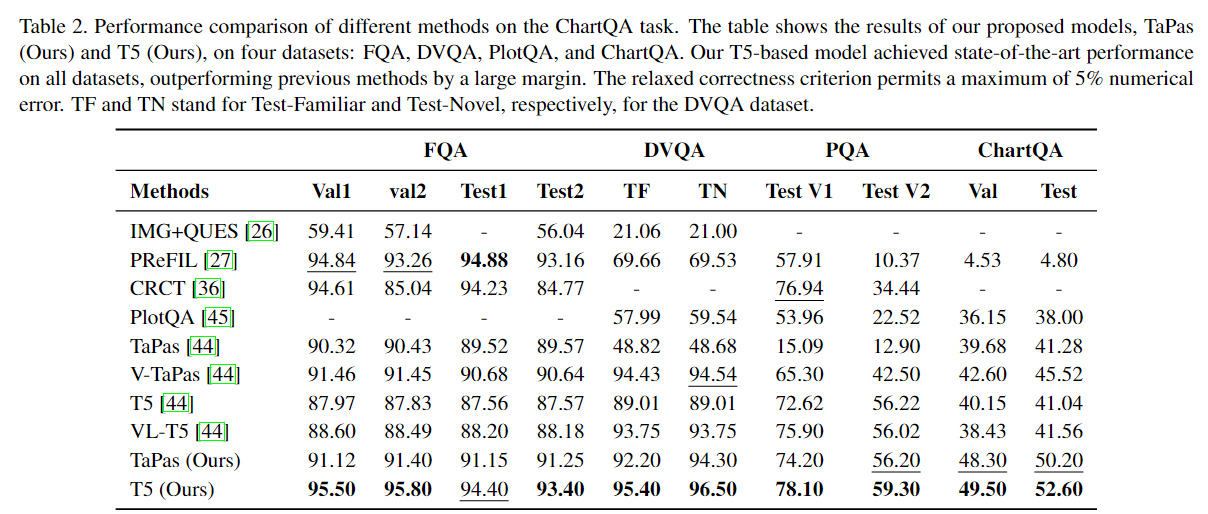
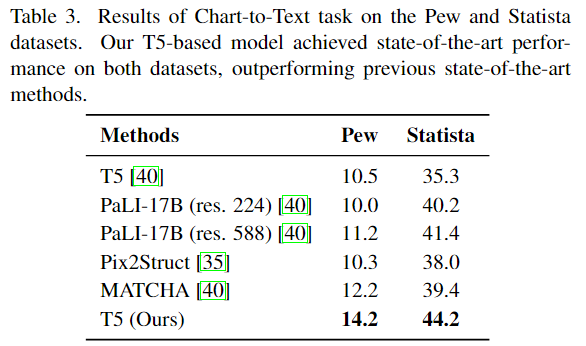
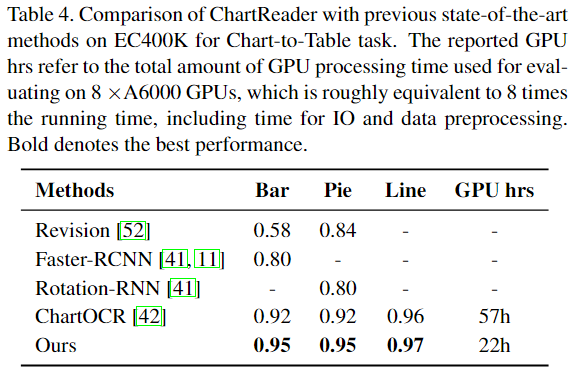
4. Experiments