
RealCQA
RealCQA: Scientific Chart Question Answering as a Test-bed for First-Order Logic
RealCQA: 科学的图表问答作为一阶逻辑的测试基础
ICDAR '23 | arvix2308
code:【传送门】
0. Abstract
我们提出了一项关于图表视觉问答(QA)任务的综合性研究,以解决在文档中理解和提取图表可视化数据所面临的挑战。尽管已经努力使用合成图表来解决这个问题,但解决方案受到现实世界数据标注不足的限制。为了填补这一空白,我们引入了一个针对真实世界图表的图表视觉QA的基准和数据集,提供了对任务的系统分析以及基于模板的图表问题创建的新型分类方法。我们的贡献包括引入了一个新的答案类型,即“列表”,包括有序和无序的变体。我们的研究基于来自科学文献的真实世界图表数据集进行,相比其他作品,展示了更高的视觉复杂性。我们的重点是基于模板的QA以及它如何作为评估模型一阶逻辑能力的标准。我们在一个真实世界的分布外数据集上进行了实验,结果对大规模预训练模型进行了稳健的评估,并推进了图表视觉QA和神经网络中形式逻辑验证的领域。
1 INTRODUCTION
最近的研究已经为问题类型分类提供了一个结构,同时在图表类型和答案类型上逐步增加复杂性。不过,目前没有任何现有的工作填补了在真实世界图表上进行结构化输出预测的 QA 的空白。
合成图表问答的两种主要方法是:(i) 将整个输入图像视为像素矩阵,以生成文本、答案类型等形式的输出;(ii)首先通过识别、分类图表结构组件来提取表格数据,然后将任务视为图表问答任务。
这些包含数字答案(回归任务)或来自图表词汇的单个字符串答案(分类任务)。作者进一步提出了结构化和非结构化的列表答案类型任务,其中答案可以包含分隔符分隔的字符串。还包含了散点图和箱线图的新图表类型,并提供了经过策划的图表特定问题。
随着对文档理解的多模态数据进行表征学习的出现,知识表示和在潜在空间中推理的任务已经显著改进,相比以前用于捕获命题逻辑的启发式驱动方法。
最近的研究可以将 $FOC_2$ (具有两个变量和计数能力的一阶逻辑)与神经网络相结合。为诸如学习对数学表达式进行推理,NSC(神经符号计算)等任务,提供了一个整洁的测试平台。
在构建基于逻辑的系统,如定理证明、猜想求解等方面,已经有着丰富的研究历史。最近的进展已经证明,使用复杂的变换器和图神经网络来进行数学推理在涉及数百万个中间逻辑步骤的非常大型数据集上非常有效。
最近一项研究声称,通过增加数学推理的预训练,合成图表问答的准确率几乎提高了 20%,尽管它们缺乏对模型推理能力的稳健评估。
为了进一步开发能够在文档理解空间中进行形式逻辑推理的模型,我们提出 RealCQA 作为一个稳健的多模态测试平台,用于逻辑和基于科学图表的问答。
2 Background
我们首先讨论文献中更常见的研究任务,这些任务为图表问答(ChartQA)提供了基础。其中包括视觉问答(visual QA)、文档理解(document understanding)和形式逻辑系统(formal logic systems)。
2.1 Visual QA
VQA,即视觉问答(Visual QA),是一项任务,其中计算机系统被提供一张图像和一个关于图像的自然语言问题,系统被期望生成一个自然语言答案[19]。VQA系统旨在模仿人类理解和推理视觉信息和语言的能力,并利用这种理解来对问题生成适当的回答。此任务的特定变体包括图像字幕生成和多模态检索。
- Image Captioning: 其中计算机系统被提供一个输入图像,并被期望生成图像内容的自然语言描述[9]。这个描述应该捕捉到图像中所描绘的主要对象、动作和事件,以及它们之间的关系。图像字幕生成系统通常使用机器学习算法从大量图像数据集和相应的人工生成字幕中学习如何生成描述性字幕。
- Multimodal Retrieval: [16]。这项任务涉及计算机视觉和自然语言处理技术的整合,并在诸如图像和文本搜索、图像注释和自动化客户服务等各种应用中使用。在图像-文本跨模态检索中,计算机系统接收一个查询,可以是图像或文本的形式,并且期望检索与查询相关的图像或文本。为了有效地执行图像-文本跨模态检索,系统必须能够理解和推理图像和文本的视觉和语言内容,并识别它们之间的关系。这通常涉及使用机器学习算法,在大型图像和文本数据集及其相应关系上进行训练。
2.2 Document Understanding
文档智能领域涵盖了广泛的任务[6],[31],例如定位、识别、布局理解、实体识别和链接。在本节中,我们描述了文档问答(Document-QA)、表格问答(Table-QA)和信息图问答(Infographic-QA)等下游任务,这些任务为图表问答(Chart-QA)奠定了基础。
VQA for Document Understanding
文档理解的VQA已经在一些研究中进行了探索,例如[36],这些研究涉及由表格、文本和问答对组成的文档页面。这些文档来自财务报告,包含大量数字,需要离散的推理能力来回答问题。关系型VQA模型使用基于一阶逻辑的推理框架来回答关于视觉场景的问题。研究人员还探索了其他类型的图表,如基于地图的QA[7]。CALM [12]提出了使用先验知识推理来扩展[25],[29]提出了用于非英文文档理解的QA模型。文档问答[DQA]的关键要求包括:
(i) 强大的特征表示:DQA的主要挑战之一是有效地表示文档的视觉和语义内容。开发能够捕捉文档中对象、属性和概念之间关系的强大特征表示是该领域研究的一个关键领域。
(ii) 大规模数据集:DQA的另一个挑战是缺乏可用于训练和评估模型的大规模数据集。开发包含各种文档和问题的大规模数据集对于推进该领域至关重要。
(iii) 先验知识和上下文的整合:为了准确地回答关于文档的问题,模型必须能够有效地将先验知识和上下文整合到其推理过程中。这需要开发能够推理文档中对象和概念之间关系的算法,并将先验知识和上下文纳入决策过程。
(iv) 关系推理:DQA经常需要推理文档中对象和概念之间的关系。
(v) 多模态融合:DQA需要整合来自多种模态的信息,包括视觉和语义内容。最近的研究包括[25],[33],[32],[28]。
Table QA
表格问答(Table QA)是一项自然语言处理(NLP)任务,涉及回答关于表格中呈现的信息的问题。这个任务要求模型理解表格的结构和内容,以及自然语言问题的含义,以生成正确的答案。表格内容以文本输入形式提供。最近在表格问答任务的文献中包括[15],[13],它们提出了一些模型,用于从关于表格的自然语言问题生成SQL查询。
2.3 Chart-VQA
我们讨论这个特定子领域的两种常见方法,输入是一个图表图像和相应的查询。
Semi-Structured Information Extraction (SIE) [24]
半结构化信息提取(SIE)[24]涉及以下步骤:(i) 图表文本分析:提取刻度标签、图例、坐标轴和图表标题,以及图像中的任何其他文本。(ii) 图表结构分析:对应数据值的刻度关联进行 xy 坐标插值,以及最近的刻度标签和图例映射到各个数据系列组件标签。(iii) 视觉元素检测[VED]:定位图表组件(线条、箱型、点、条形)并将其与 x 刻度和图例名称进行关联。(iv) 数据提取:使用VED模块对每个数据组件表示的值进行插值,并根据边界刻度计算值。
这将图表问答(Chart-VQA)转化为表格问答(Table-VQA)任务。然而,这增加了额外的复杂性,因为现在在数据提取任务期间也会引入错误。
Classification-Regression [20], [26]
分类-回归[20],[26]方法已被证明对图表理解是有效的,允许机器学习模型准确地分类和预测图表中所描述的值和趋势。在这种思路中,输入直接被视为像素,通常依赖于图表组件、绘图区域、视觉元素和基础数据的隐式表示。这些特征与问题字符串的文本特征一起聚合在一起,模型学习它们之间的对应关系,以预测分类答案(字符串)或回归答案(数字)。通常,模型使用基于Mask-RCNN的骨干网络提取视觉特征,该网络经过训练可以检测图表的文本和结构。这些特征与经过标记的文本查询一起输入。答案预测涉及预测数值或字符串类型,其中浮点数是进行回归,而标记是进行分类。
2.4 Logic Order and Reasoning
我们讨论形式逻辑、测试平台的要求以及在图表问答(Chart-QA)的背景下的适用性。
Zero-order logic [ZOL]
零阶逻辑(Zero-order logic,ZOL)是意义的基本单元,即原子公式,它是一个陈述性命题,例如回答根级分类问题:‘这个图表是类型A吗’,‘图表中有标题吗’,‘依赖轴是对数的吗’等。复杂的陈述可以通过使用逻辑连接词(例如’和’,‘或’ 以及 ‘非’)来组合原子公式来形成。
First-order logic [FOL]
一阶逻辑(First-order logic,FOL)也称为谓词逻辑,是一种形式逻辑,用于研究对象及其属性之间的关系。它允许表达关于属性和关系的命题或陈述,提供了一种基于这些陈述进行逻辑推断的形式语言。在一阶逻辑中,我们有量词∀(对于所有)和∃(存在)来对论域的整个范围进行陈述,涉及变量,这些变量在讨论的对象上范围,例如图表中所有刻度标签的封闭集。我们可以使用一元谓词或多元谓词分别谈论这些对象的属性或它们之间的关系,例如比较不同刻度位置的数据系列值。这些谓词可以被视为集合,其中它们的元素是满足某些属性的域中的元素,或者是满足某些关系的n元组,“⟨Y标题⟩在⟨第 i 个 x 刻度⟩和⟨第 (i + 1) 个 x 刻度⟩的值之和是否大于所有⟨ X 标题的复数形式⟩中的最大值?”
N-th order logic
第n阶逻辑使用相同的量词来对谓词进行范围限定。这本质上允许集合的量化。根据需要,可以使用量词来对集合的元素进行临时量化。这涉及具有结构化输出的’列表’类型问题,例如“独立轴上哪些主刻度对于⟨Y标题⟩的值,其差异大于⟨i-th x刻度⟩和⟨j-th x刻度⟩,并按差异的增加顺序排列?”为了更好地评估,我们将当前范围限制在第二阶逻辑中,即我们创建的问题中,列表中每个项目的最多有2个元素的集合输出,如图2所示。

A Testbed for Formal Logic
形式逻辑的测试平台必须满足特定的要求,以确保被测试系统的正确性。第一个要求是正式规范,应该精确定义系统的语法、语义和模型检查算法。第二个要求是一组测试用例,涵盖所有可能的情况,并验证系统的行为,包括其处理边缘情况和异常条件的能力。第三个要求是一个可重复、可靠且易于扩展的测试框架,可以容纳新的测试用例。最后,必须创建一个验证环境来托管测试平台,并提供执行测试所需的必要资源。
这些要求确保了对形式逻辑系统进行了全面的测试,并且测试结果是准确可靠的。满足这些要求所使用的具体要求和技术的性质将取决于正在测试的系统以及其使用的上下文。总的来说,严格的测试对于确定逻辑系统的正确性并确保其适用于实际问题至关重要。**现有的用于评估图表问答的实验设置满足了上述大部分要求,除了正式规范,我们为我们问题的一个子集提供了正式规范。这些问题是手工筛选和验证的。**我们将详细描述这一点。
CQA for FOL
CQA for FOL代表了我们利用基于模板的图表问答任务作为谓词逻辑测试平台的概念。填充科学图表的数据的固有结构与先前提到的正式规范要求自然契合。先前的研究已经研究了带有图表的VQA,然而,正式测试平台尚未被研究。在FOL中,句子以特定的语法和结构编写,以便精确而明确地表示含义。要将普通句子翻译成FOL,我们需要识别句子中描述的对象、个体和关系,并使用谓词、变量和逻辑连接词来表示它们。例如,模板"⟨Y标题⟩在⟨i-th x刻度⟩和⟨j-th x刻度⟩的值之差是否大于任意两个⟨X标题的复数形式⟩之间的差异?"可以转换为FOL形式:
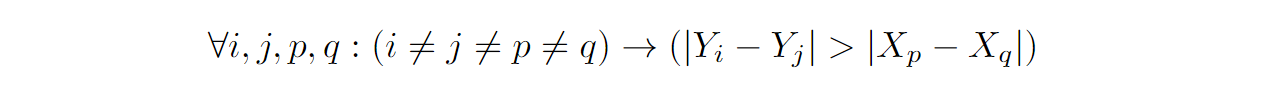
其中⟨…⟩代表模板中的变量,'Y’代表依赖变量的取值空间,'X’代表图表中的自变量。在筛选推理类型[17]问题时,我们创建了一个特定于FOL的二元问题子集,这些问题是有效的。
在这项研究中,我们的目标是进一步推进图表和视觉数据解析系统的发展。先前的研究已经记录了由于有限的标注真实世界数据可用性而造成的限制[11]。虽然在特定的ChartQA数据集上的绝对准确性可能无法保证广泛的泛化能力,但这项研究是朝着建立对这个复杂且不断发展的领域的全面理解迈出的一步。我们认为,利用手工筛选的模板和从图表的语义结构生成的结构化输出为现代神经网络(如大规模预训练语言和布局模型)的多模态谓词逻辑解析能力提供了一个有效评估的机会。
3 Dataset
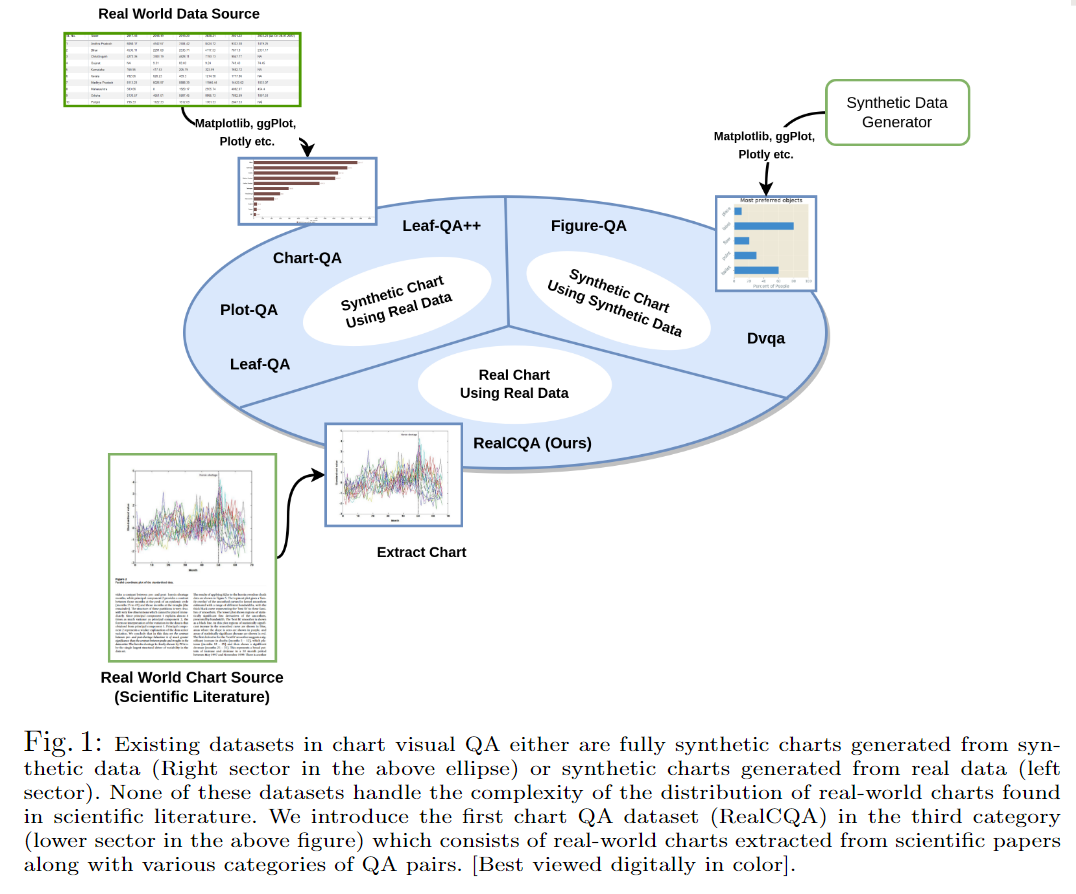
在本节中,我们描述了我们研究中使用的数据集。该数据集名为RealCQA,是通过利用公开进行的图表理解挑战中使用的真实世界图表图像和注释而创建的[11]。图1显示了CQA领域中当前存在的数据集。图3显示了围绕图表理解的挑战任务,以及从公开发布的训练-测试拆分中使用的注释数据。

3.1 RealCQA
为了生成RealCQA的问题模板,我们从之前的工作[8],[30]和[26]中编译了模板。这些模板被调整以适应我们的数据,并增加了新的图表类型问题、列表问题和二元FOL推理问题,总共形成了240个模板。
RealCQA的分类和答案类型分布如图4所示。我们尝试保持不同答案类型的模板具有相等的比例。然而,当这些模板用于创建实际的问答对时,数据会根据底层可用性而变得倾斜。我们的数据集主要由“推理”类型的问题组成,这与先前的研究[17]中所见相符。然而,我们还专注于创建满足FOL的二元推理问题。由于具有i-th/j-th刻度/数据系列变量的模板具有组合性质,我们对图表中存在的对象的封闭集进行了详尽的创建,这些问题构成了数据集的主要部分。
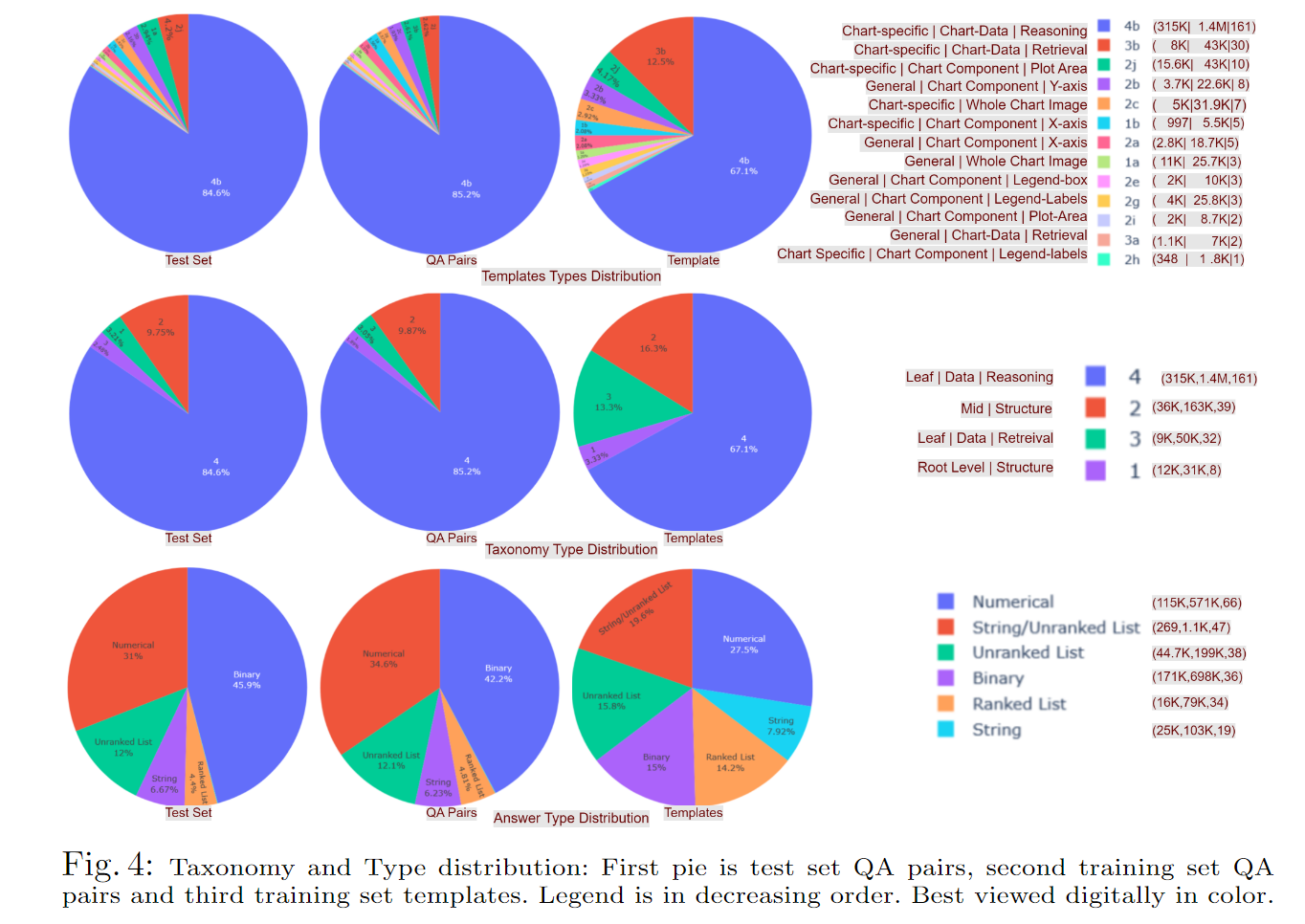
我们使用先前研究中提出的“结构、检索、推理”分类法[17]对我们的问题进行分类。然而,我们根据它们的特征进一步划分为类型1、2、3、4。类型1指的是可以在整个图表图像(根)级别形成的任何问题,主要是ZOL。类型2进一步指的是特定图表组件的ZOL问题,需要模型识别它们。类型3和类型4是数据检索/推理。每种类型都有一个进一步的特定子类,取决于具体的组件、图表类型等,如图4所示。
数据集的统计信息如图5所示,使用了先前的“结构”、“检索”和“推理”的命名法。对于列表类型,我们只为第k阶FOL测试筛选推理问题。字符串/无序是指一小部分字符串类型的检索或推理答案,其中存在多个等价条件。在阅读问题字符串时,人类会期望得到一个单一的答案,但是多个数据系列具有相同的最大/最小值,导致多个正确的单一字符串实例答案。这些通常是异常值。
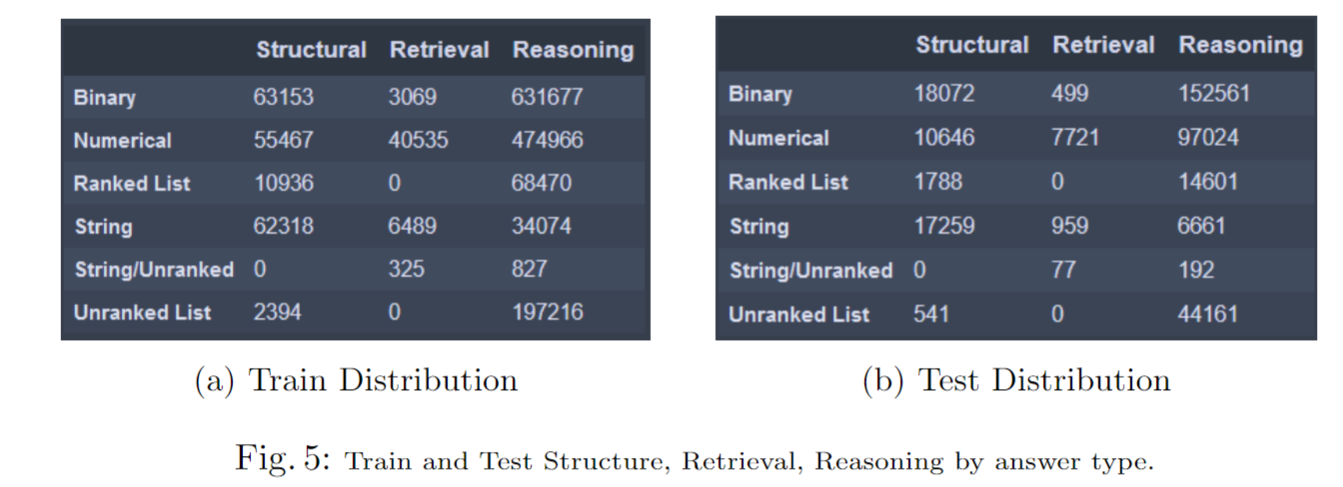
总的来说,RealCQA数据集提供了一系列不同类型的问题,需要各种不同水平的图表理解和推理能力。该数据集已公开可用,可用于图表理解领域的进一步研究和评估。
3.2 Sampling Strategies for Dataset Evaluation
数据集评估的采样策略
对于一般的图表视觉问答,生成平衡和代表性的数据集对于训练和评估模型至关重要。然而,当涉及到逻辑测试平台时,特定模板或问题类型的过度代表并不一定是一个劣势,因为它允许更细致地评估模型的逻辑推理能力。尽管如此,探索数据集采样对评估结果的影响仍然是相关的。
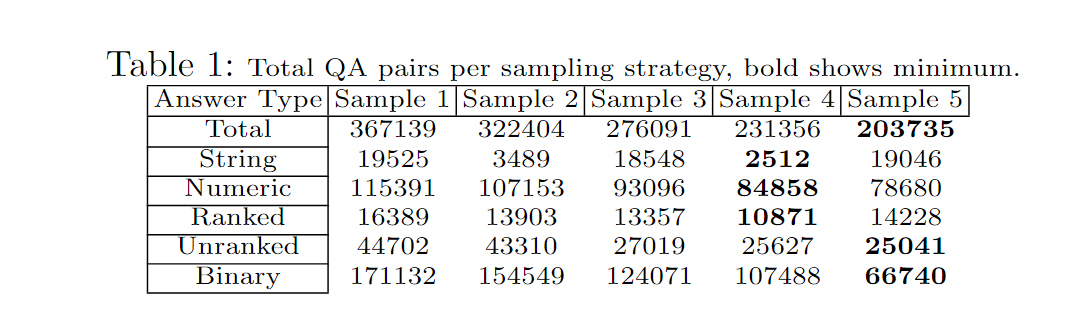
为此,我们设计了五种不同的采样策略,并评估它们对我们数据集的影响。第一种策略是穷举采样,包括所有可用的问题-答案对。其余的策略旨在根据不同的标准修改每个图表的问题分布。具体而言,第二种策略,增加下限,侧重于具有问题最小数量大于或等于阈值K的图表。该策略旨在解决低频问题类型,例如根和结构问题。相反,第三种策略,降低上限,选择具有问题最大数量小于或等于阈值L的图表。该策略旨在解决高频问题类型,通常是组合二元推理问题。第四种策略结合了第二和第三种策略的效果,旨在消除低频和高频图表。最后,第五种策略,平坦上限,每个模板每个图表选择固定数量的问题,从而创建一个更均匀的数据集。
图6说明了不同的采样策略如何影响每个图表每个模板的问题数量,而表1提供了每种采样的实际问题-答案对数量。具体而言,我们计算了第二和第三种策略的下10%和上10%。对于平坦上限策略,我们每个图表每个模板随机选择了150个问题-答案对。
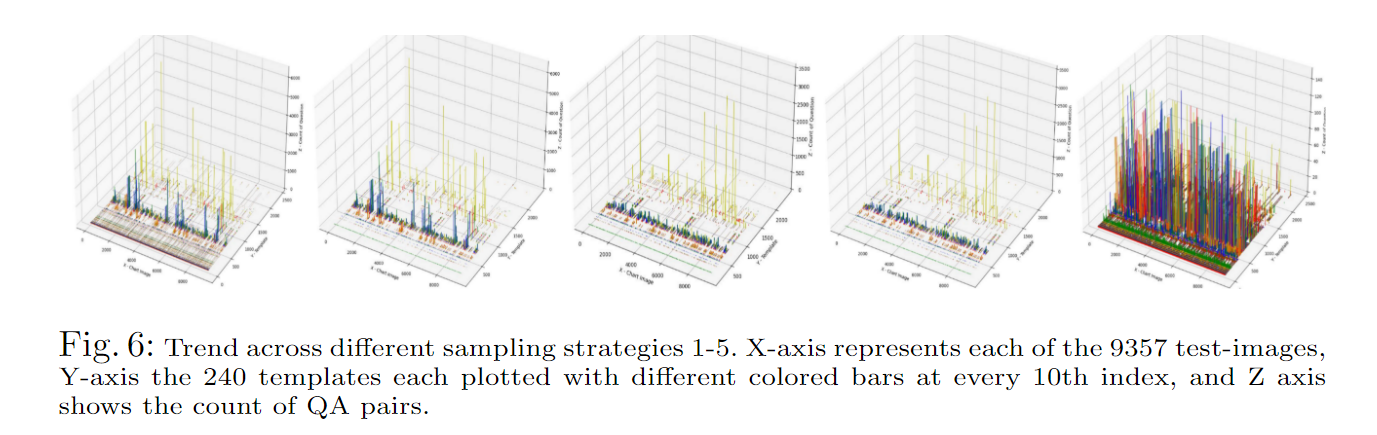
通过分析不同采样策略的影响,我们可以更好地了解如何移除测试集中的特定部分会影响评估结果。这些发现对于根据需要调整训练集,并最终开发更健壮和准确的视觉问答模型是有用的。
3.3 Evaluation Metrics
在这项研究中,我们提出了一种基于答案准确性的评估指标。所提出的任务涉及四种类型的答案,每种都有其特定的计算方法。
首先,对于数值答案,我们使用L2或L1差异或ER误差率来测量回归误差的准确性。在PlotQA-D [1]中,我们认为如果回归答案在真值的±5%容差范围内,则答案是正确的。其次,对于单字符串答案,我们使用字符串匹配编辑距离,并将完全匹配视为正确。第三,对于无序字符串列表,我们使用字符串匹配编辑距离。对于每个K个查询和M个匹配,我们计算K×M个分数,然后通过每个字符串实例的彼此互斥的最佳匹配来进行归一化处理。第四,对于排名顺序的字符串列表,我们使用nDCG@K排名指标,其中K是真值列表的大小。nDCG是DCG(折现累积增益)指标的标准化版本,它被广泛用于评估信息检索系统的排名质量,例如搜索引擎和推荐系统。该指标根据用户的偏好为排名列表中的每个项目分配相关性分数,然后使用对数函数对这些分数进行折现,排名较低的项目获得较低的分数。最后,对于嵌套列表,其中每个项目都是一个集合,我们评估结果与集合顺序无关,但在排名列表中列表顺序很重要。
4 Experiments
我们在RealCQA上对多个现有的通用视觉问答和专门用于图表的视觉问答方法进行基准测试。图7显示了用于CQA任务的通用现有架构。模型要么单独学习视觉和数据特征,要么在同一个共享空间中学习,然后使用某种融合模型生成最终答案。这些模型主要是在合成图表上进行训练的。在这里,我们评估了最近提出的多个基线模型,包括ChartQA和CRCT。我们提出了在RealCQA上的合成预训练评估和RealCQA微调评估。下面我们简要讨论更多细节的基线方法的模型架构:
VLT5 [10]
VLT5是一种最先进的统一框架,利用多模态文本调节语言目标,在统一的架构中执行不同的任务。在这个框架中,模型学习根据视觉和文本输入在文本空间中生成标签。在我们的研究中,我们使用VLT5来执行基于表格的问答任务。具体而言,VLT5的输入是从Faster-RCNN获取的预训练的基于区域的视觉特征,该模型在PlotQA上进行了预训练。这些视觉特征,连同文本标记,被投影并通过一个统一的双向多模态编码器传递。此外,在自回归设置中训练了一个语言解码器来执行文本生成。在文本环境中,我们提供了一个预先提取的金标准图表作为与查询问题连接的输入。
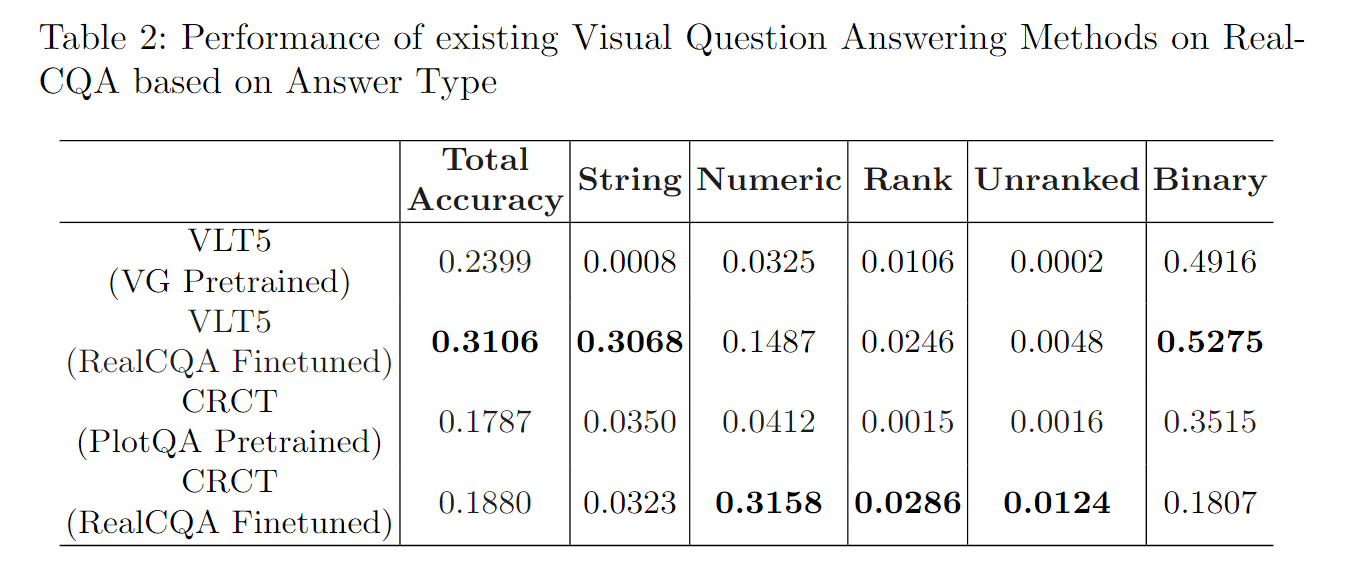
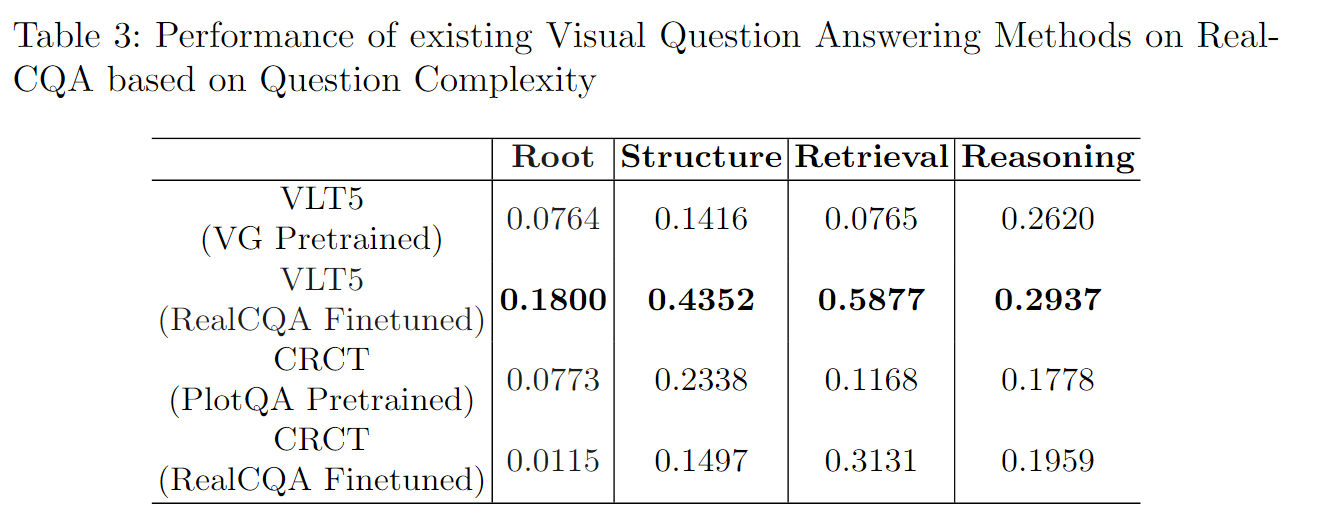
我们在RealCQA测试集上展示了VLT5的性能,该测试集包含大约683个具有金标准数据表注释的图表。评估是在这个测试集中的图表上进行的,未涉及的图表被分配了零分。评估结果如表2和表3所示,其中第1行分别显示了VLT5按答案类型和问题类型分组的性能。
ChartQA [24]
ChartQA的作者介绍了一个大规模基准数据集,包含了9.6K个人工编写的问题和23.1K个从人工编写的图表摘要生成的问题。为了评估数据集的有效性,他们使用数据表和视觉特征作为上下文,在ChartQA上对两种基于Transformer的多模态架构——VisionTapas和VLT5进行了基准测试。
在本研究中,我们使用了在PlotQA上预训练的ChartQA视觉特征,对VLT5多模态编码器进行了微调。我们在表2和表3的第1行和第2行中分别使用了ChartQA预训练的Mask RCNN视觉特征和VLT5多模态注意力。根据答案类型和问题类型对结果进行了分组,如表2和表3所示。由于评估需要数据表,我们在683个图表上对模型进行了评估,并将剩余的QA分数设为零。
CRCT
CRCT(分类回归图表变换器)是一种新颖的ChartVQA方法,旨在解决该领域现有方法的局限性。论文作者认为,先前方法的饱和是由于常见数据集和基准测试中的偏见、过度简化和分类导向的问答所致。为了克服这些挑战,CRCT模型利用了一个带有图表元素检测器的双分支变换器,从图表中提取文本和视觉信息。该模型还具有对图表中所有文本元素的联合处理,以捕获元素之间的内部和内部关系。
提出的混合预测头将分类和回归统一到单个模型中,使用多任务学习优化端到端方法。对于视觉上下文,他们在PlotQA上对Mask-RCNN进行了微调,而对于文本上下文,他们使用了标准OCR(如tesseract)的文本检测和识别输出。我们评估了一个完全在PlotQA数据集上预训练的CRCT模型,以及一个在第二阶段使用预训练FasterRCNN对RealCQA进行微调的CRCT模型。我们分别在表2和表3的第3行和第4行报告了这两个模型的性能。
4.1 Results
我们在表2和表3中总结了我们实验的定量结果。我们发现,使用预训练的Mask RCNN视觉特征和RealCQA的金标数据表作为输入时,VLT5模型的性能不佳。对于二进制类型答案的性能为49.16%,与随机分配一样糟糕。然而,通过在RealCQA上微调VLT5模型的多模态对齐模块,并修改标记化以处理列表类型答案,我们观察到在所有答案类型(表1)和问题类型(表2)上的性能显著提高。具体而言,字符串类型答案的性能从0.008%提高到30.68%,QA对的整体准确率从23.99%提高到31.06%。表3比较了完全在PlotQA上预训练的CRCT模型和VG预训练的VLT5在根、结构和检索类型问题上的性能。我们发现,完全预训练的CRCT在这些问题类型上的表现优于VG预训练的VLT5。然而,将CRCT模型在RealCQA上进行微调会显著提高数值、排名列表和无排名列表类型答案的性能,如表2所示。值得注意的是,微调后的CRCT在数值类型答案上取得了31.58%的最佳性能。我们的结果突显了RealCQA作为评估图表视觉QA方法的标准测试平台的重要性,因为即使在合成数据集(如PlotQA和FigureQA)上表现良好的模型也难以推广到真实世界的图表分布。
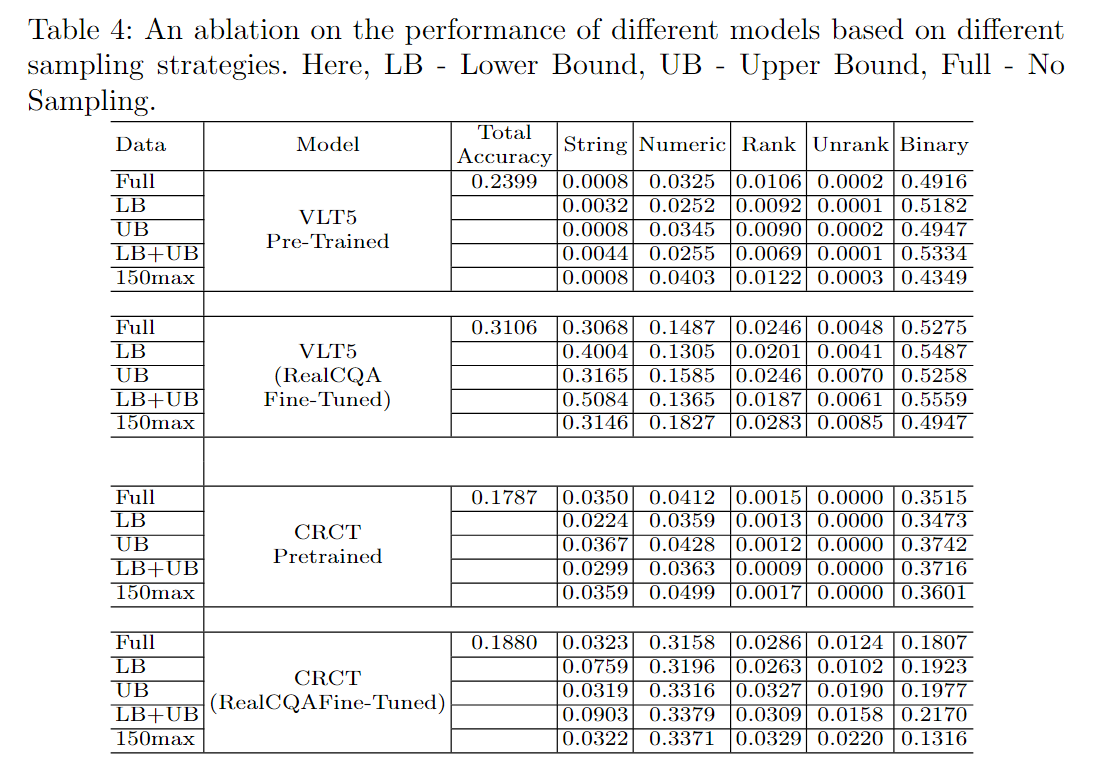
我们进行了消融研究,检查了不同采样策略对模型性能的影响。该研究的结果总结在表4中。研究表明,第4个采样策略,即同时考虑上限和下限的策略,在各种实验设置下始终实现了最高的整体、字符串和二进制类型的准确率。另一方面,第5个策略,即产生最均匀的测试集的策略,为数值和列表类型的答案提供了最高的准确率。然而,这个策略在整体、无排序和二进制问题方面的规模最小,并且对无排序列表类型问题的准确率最高,这些问题代表了第K阶逻辑问题。值得注意的是,第5个策略可能会删除大部分具有挑战性的问答对,使其对我们的目标不太理想。
5 Conclusion
除了我们提供的新颖的FOL测试平台和用于真实图表CQA评估的数据集之外,我们还对RealCQA数据集上的几种最先进的视觉问答模型进行了彻底的评估。我们的实验表明,虽然一些模型在PlotQA和FigureQA等合成数据集上表现良好,但当在RealCQA上进行测试时,它们的性能显著下降,这证明了像RealCQA这样更为真实和具有挑战性的基准测试的必要性。我们已经表明,我们提出的方法CRCT在几种问题类型上显著优于以前的模型,特别是在数值类型问题上。我们的消融研究进一步突显了构建多样化和具有代表性的测试集时采样策略的重要性。
总的来说,我们的研究强调了多模态学习和推理在视觉问答中的重要性,并提供了对当前最先进模型的局限性和机遇的见解。未来的工作可以基于我们的发现,探索更复杂的模型,更有效地整合文本、图像和推理,以及开发新的评估指标,捕捉真实世界图表问题的全部复杂性。此外,扩展数据集以涵盖更广泛的图表类型和复杂度,可以进一步提高视觉问答模型的泛化能力,并在数据分析和决策等领域实现更有影响力的应用。




