
模型压缩方法
模型压缩方法
剪枝、蒸馏、量化、二值化。

参考视频:
理论【传送门】【传送门】【传送门】【MIT的模型压缩与优化】
1. 量化
将高精度降为低比特。
模型量化是指将神经网络中的连续取值的权重或激活值近似为有限多个离散值的过程。
优势:
- 压缩参数
- 提升速度
- 降低内存占用
劣势:
- 模型精度下降
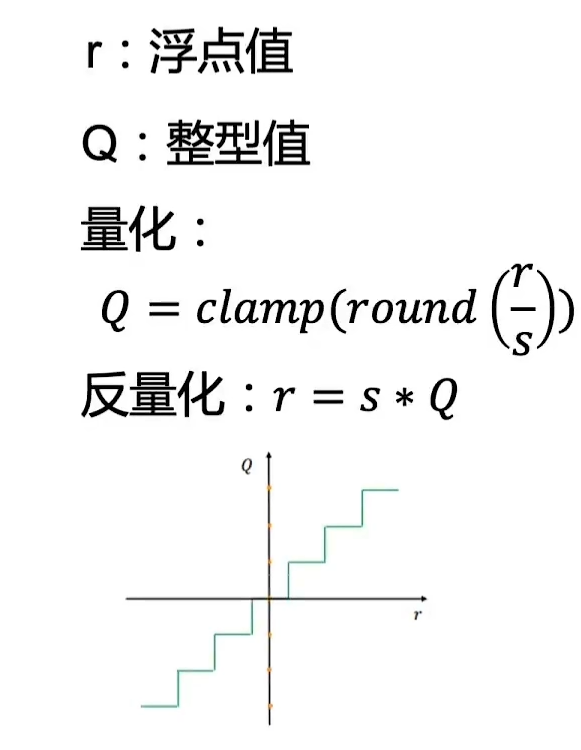
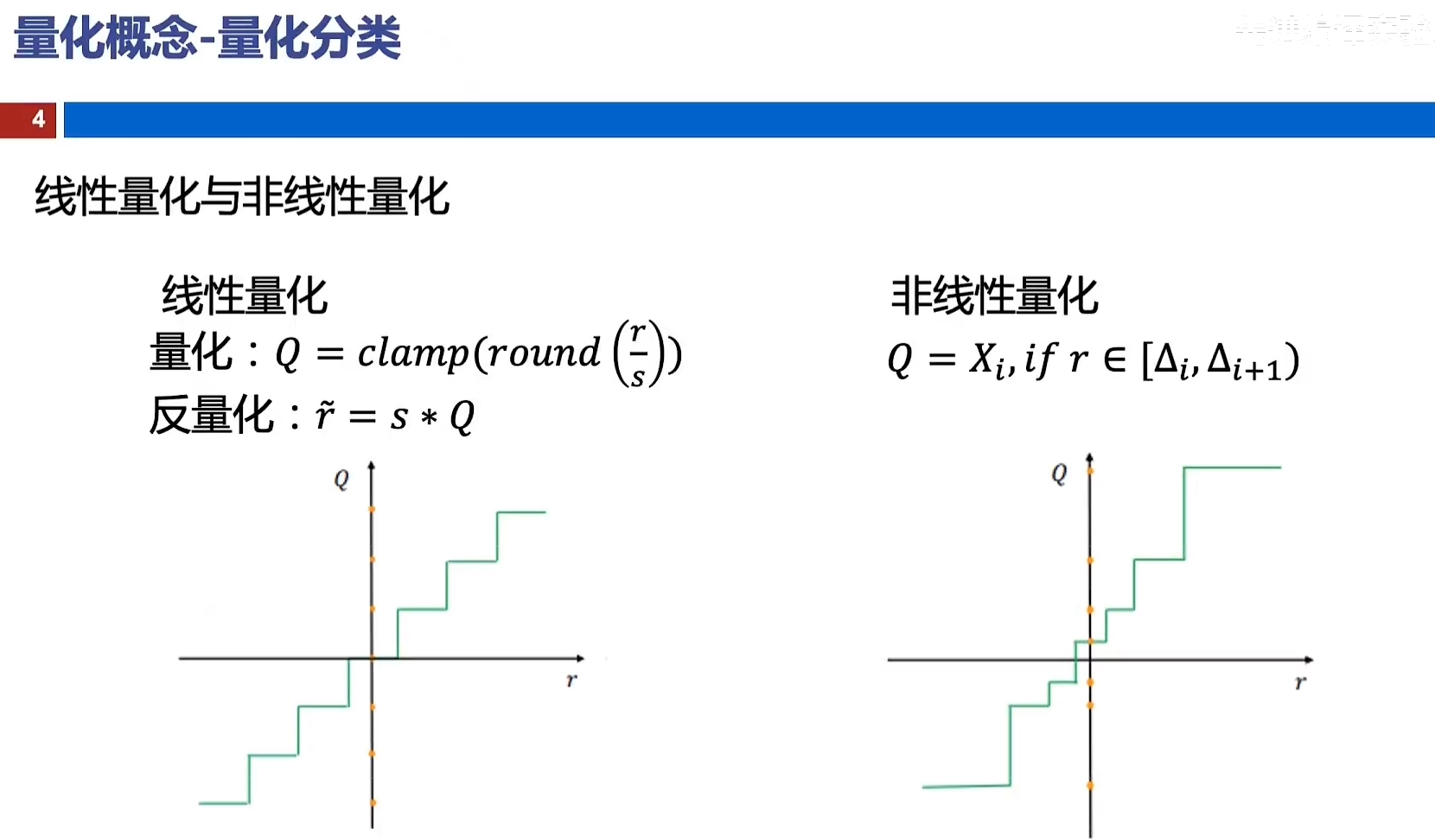
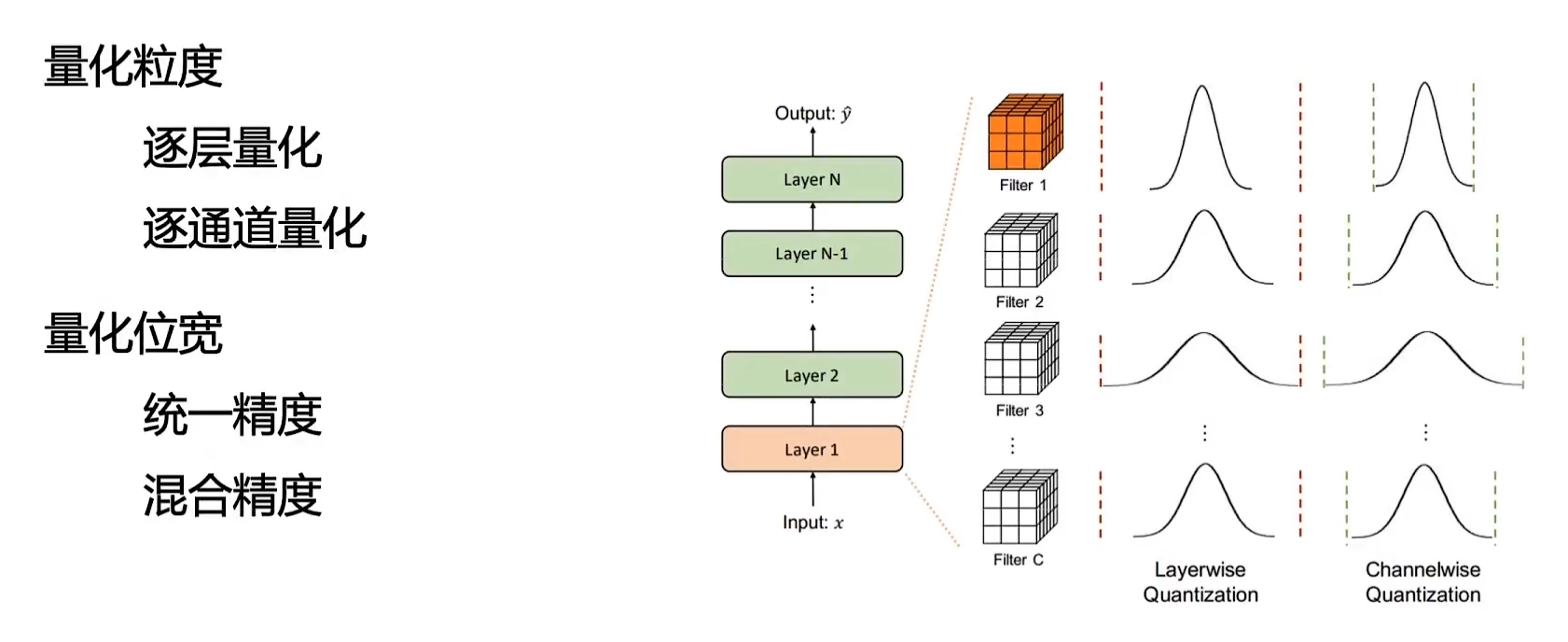
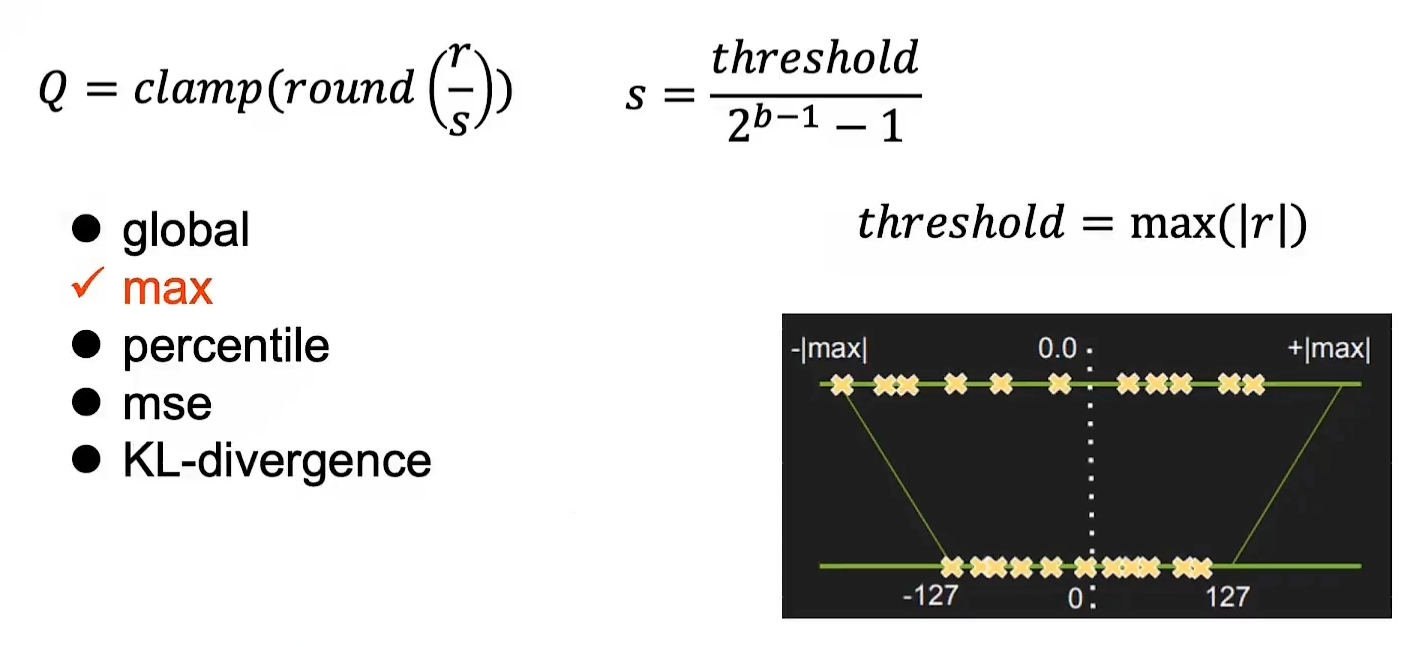
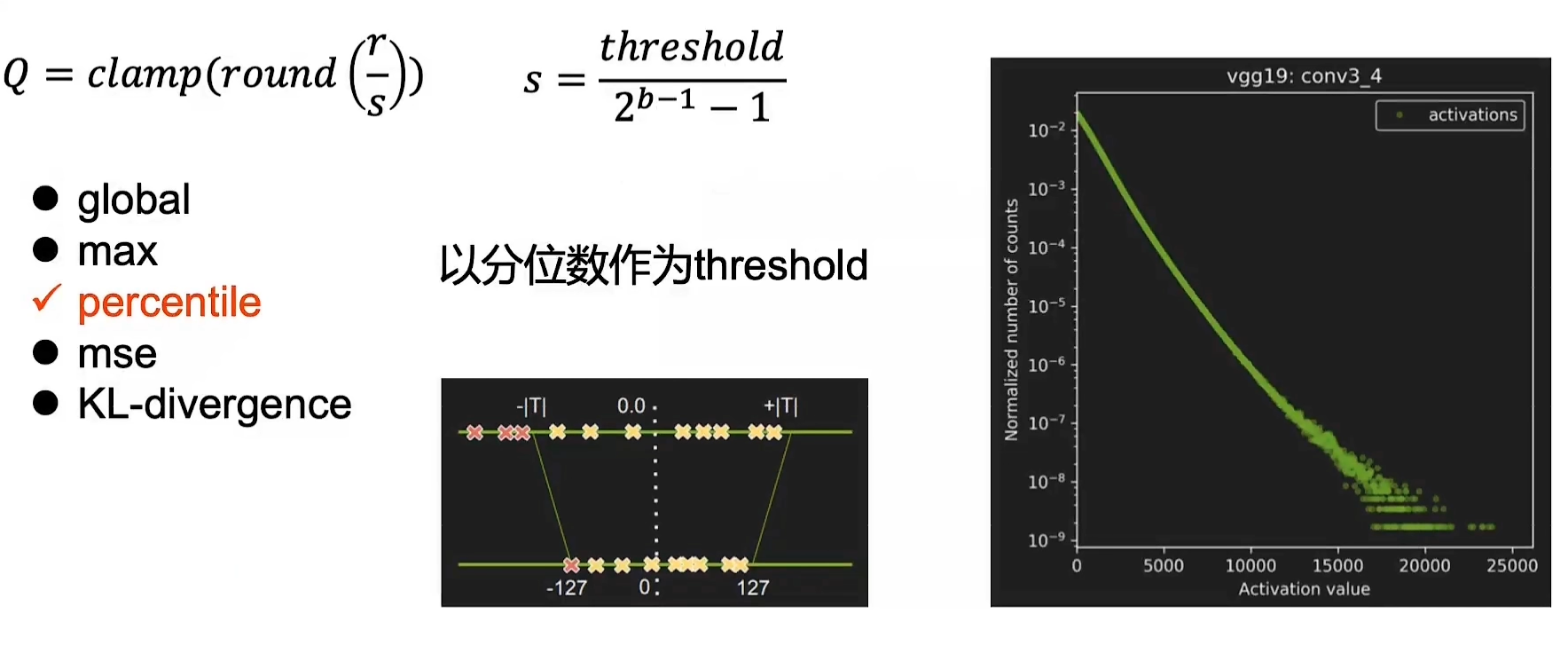


量化方法:
-
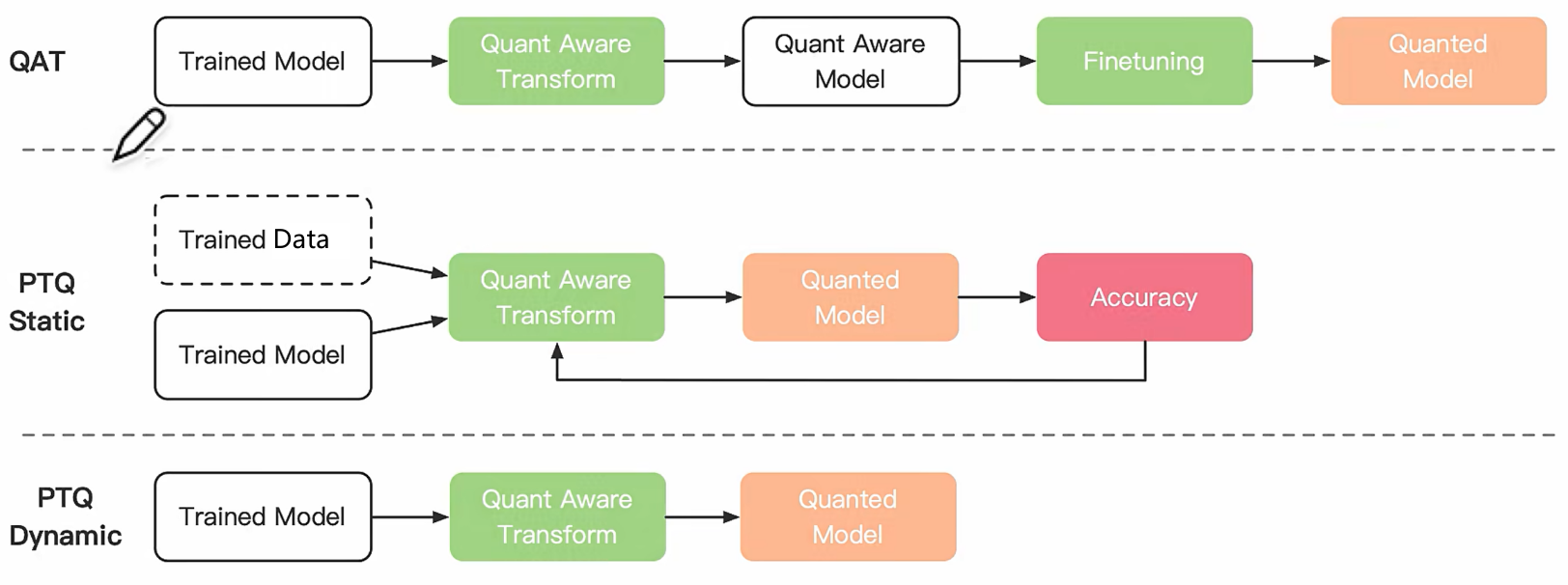
量化训练(Quant Aware Training, QAT)
量化训练让模型感知量化运算对模型精度带来的影响,通过finetune训练降低量化误差。
-
动态离线量化(Post Training Quantization Dynamic, PTQ Dynamic)
动态离线量化仅将模型中特定算子的权重从FP32类型映射成 INT8/16 类型。
-
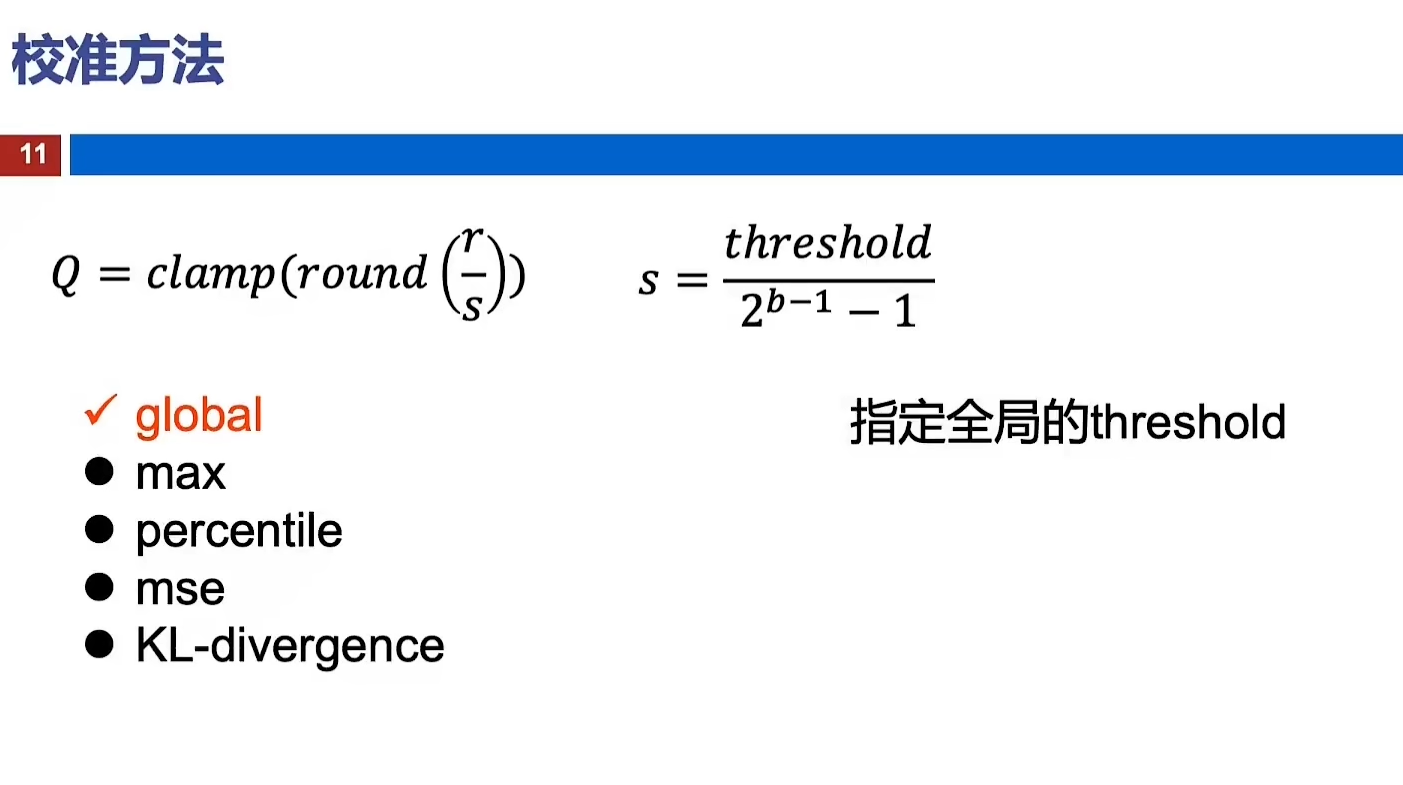
静态离线量化(Post Training Quantization Static, PTQ Static)
静态离线量化使用少量无标签校准数据,采用KL散度等方法计算量化比例因子。

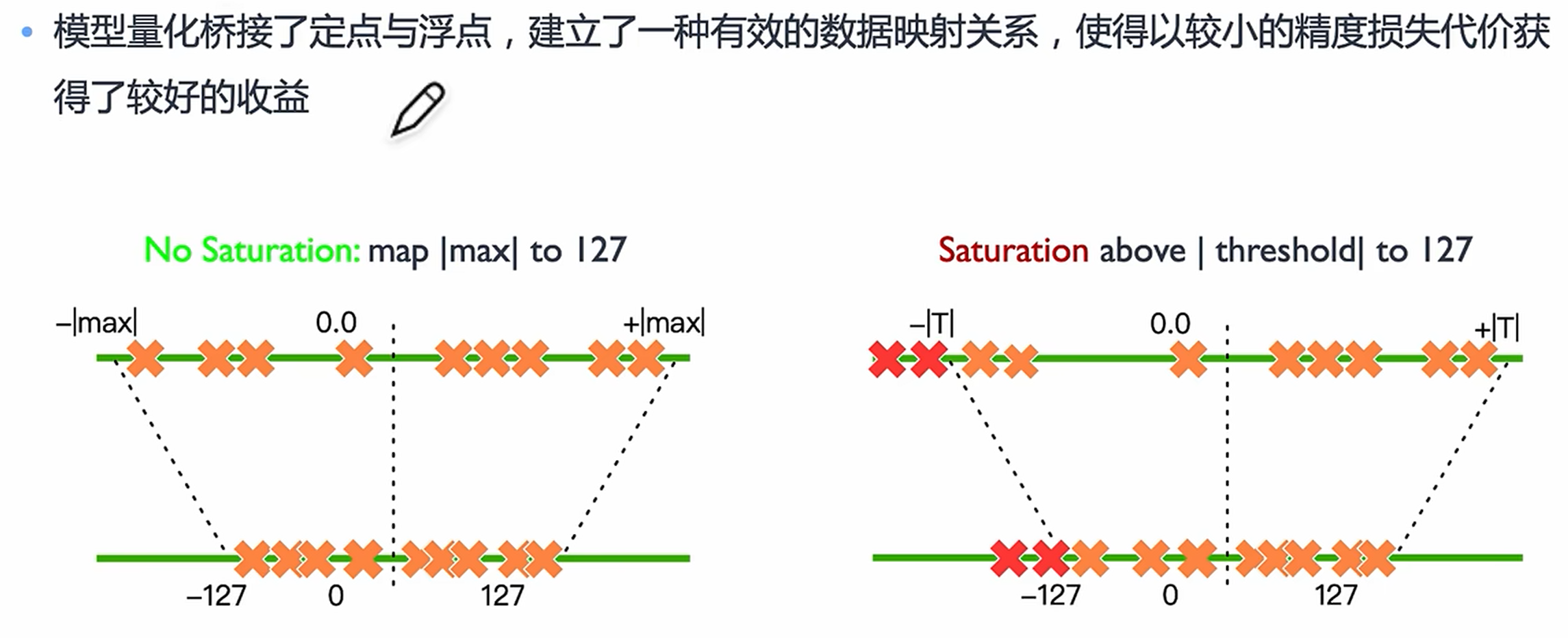
2. 模型剪枝
模型剪枝分类
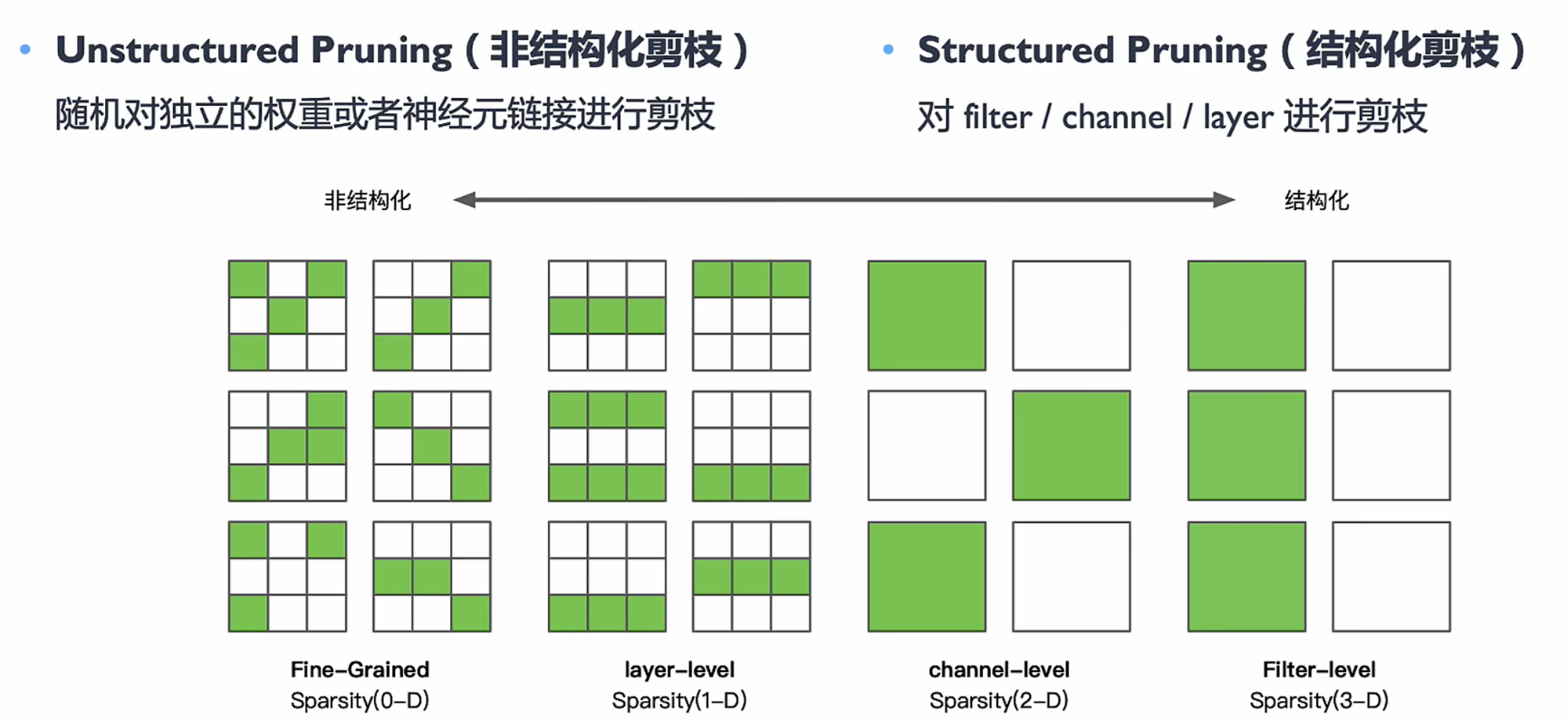
-
Unstructured Pruning(非结构化剪枝)
-
Pros:剪枝算法简单,模型压缩比高
-
Cons:精度不可控,剪枝后权重矩阵稀疏,没有专用硬件难以实现压缩和加速的效果
-
方法:
-
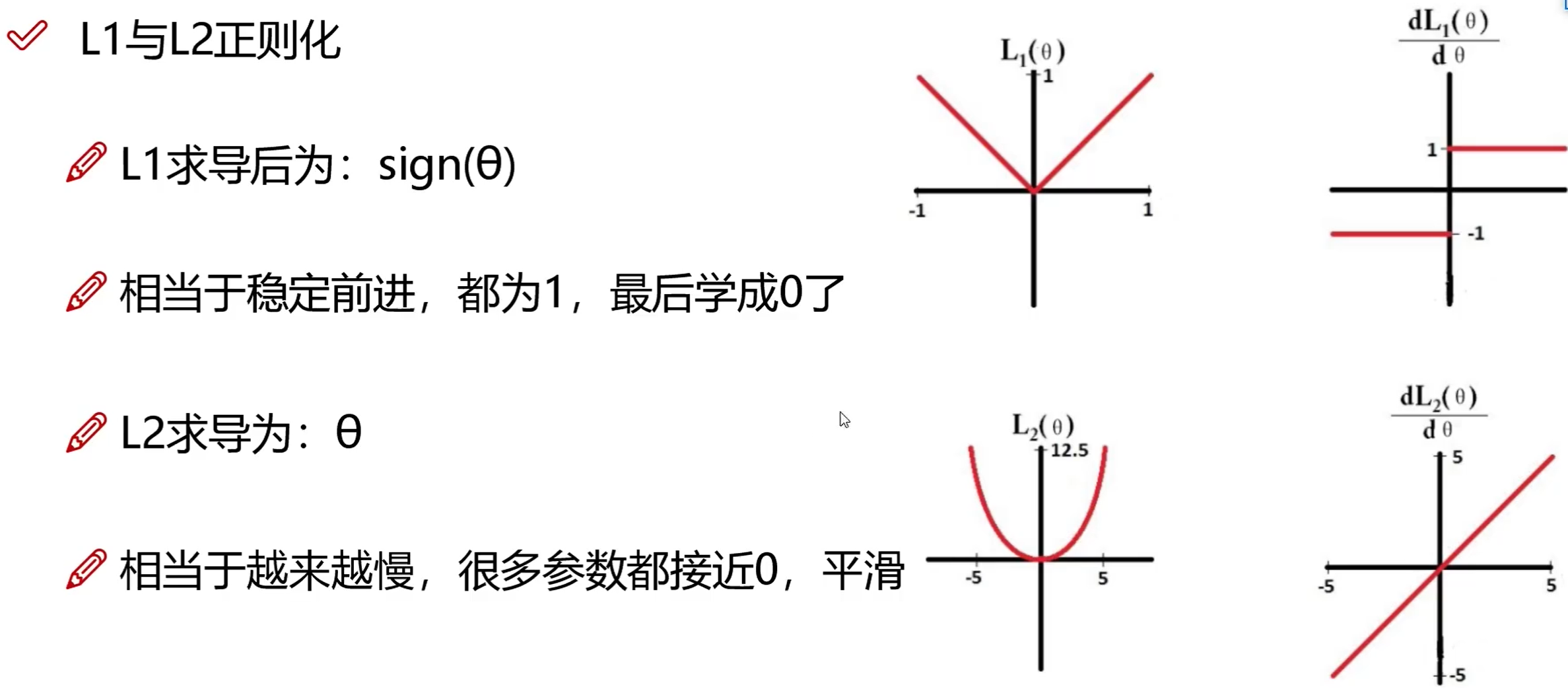
最简单的方法是定义一个阈值,低于这个阈值的权重被减去,高于的被保留。
缺点:
- 阈值与稀疏性没有直接联系;
- 不同的层应该具有不同的灵敏度;
- 这样设置阈值可能会剪掉太多信息没无法恢复原来的精度。
-
还有一种方法是使用一个拼接函数来屏蔽权重
$$
\Delta w=-\eta \frac{\partial \mathcal{L}}{\partial(h(w) w)}
$$
里面 $h(w)$ 逐渐将不必要的权重减少到0。
$$
h(w)= \begin{cases}0, & \text { if } a>|w|, \ T, & \text { if } a \leq|w|<b \ 1, & \text { if } b \leq|w|\end{cases}
$$
-
-
-
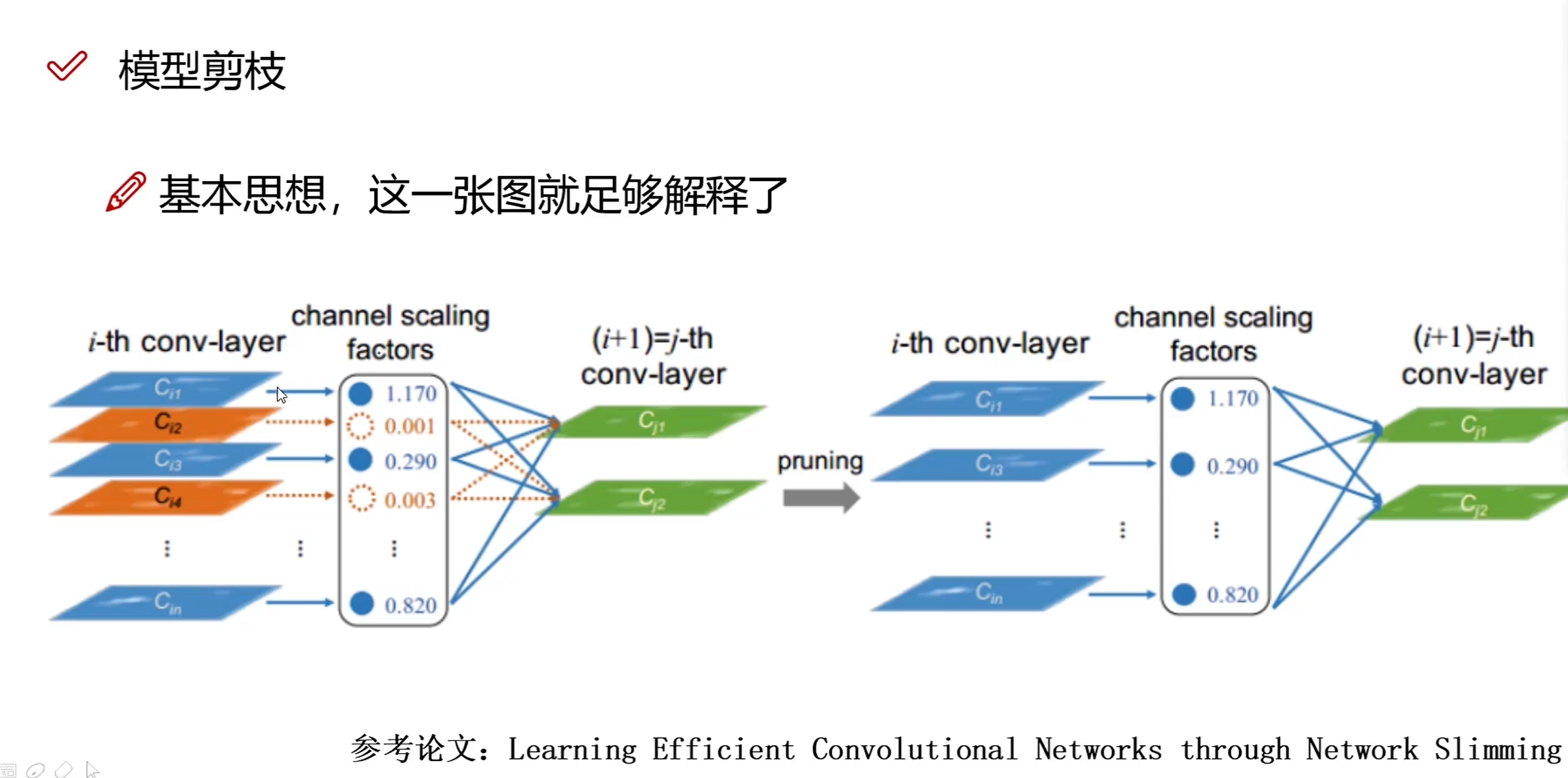
Structured Pruning(结构化剪枝)
- Pros:大部分算法在channel或者layer上进行剪枝,保留原始卷积结构,不需要专用硬件来实现
- Cons:剪枝算法复杂
模型剪枝流程
三种常见做法:
- 训练一个模型 -》 对模型进行剪枝 -》对剪枝后的模型进行微调
- 在模型训练过程中进行剪枝-》对剪枝后的模型进行微调
- 进行剪枝-》从头训练剪枝后的模型
1. 静态剪枝
静态剪枝在训练后和推理前进行剪枝、在推理过程中,不需要对网络进行额外的剪枝。
静态剪枝通常包括三个部分:
1 剪枝参数的选择;
2 剪枝的方法;
3 选择性微调或再训练
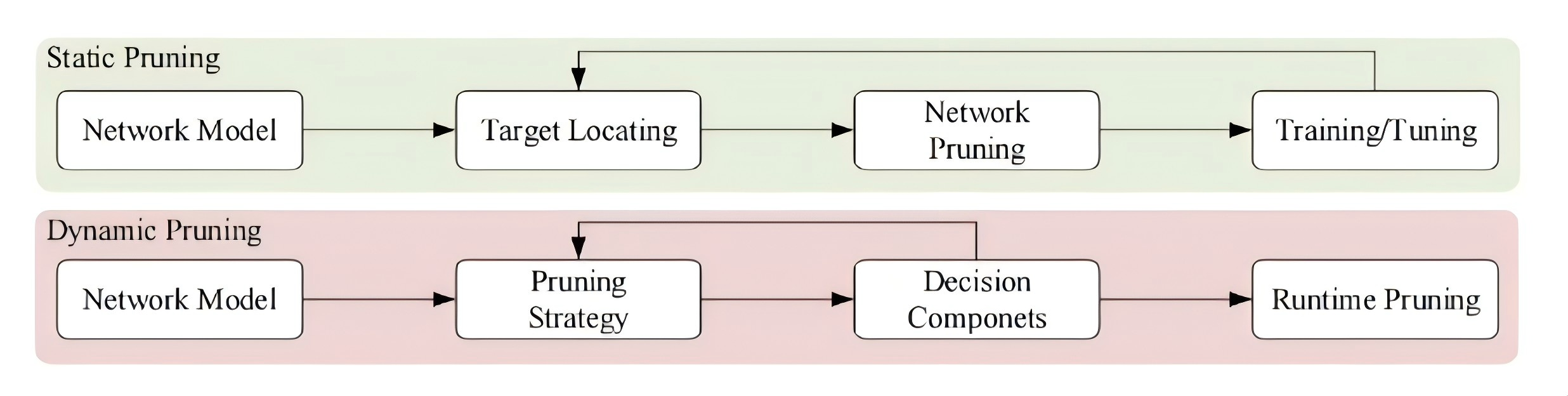
静态剪枝,储存成本低,适用于资源有限的边缘设备。
缺点:
- 通道的删除是永久性的,某些通道被永久性的减掉后,对于一些较为复杂的输入数据可能无法达到很好的精度;
- 需要精心设计需要剪掉的部分,不然很容易造成计算资源的浪费;
- 神经元的重要性并不是静态的,很大程度上依赖于输入数据,静态的剪枝很容易降低模型的推理性能。
2. 动态剪枝
网络中有一些奇怪的权重,他们在某些迭代中作用不大,但在其他的迭代却很重要。动态剪枝就是通过动态的恢复权重来得到更好的网络性能。动态剪枝在运行时才决定哪些层、通道或滤波器不会参与进一步的活动。
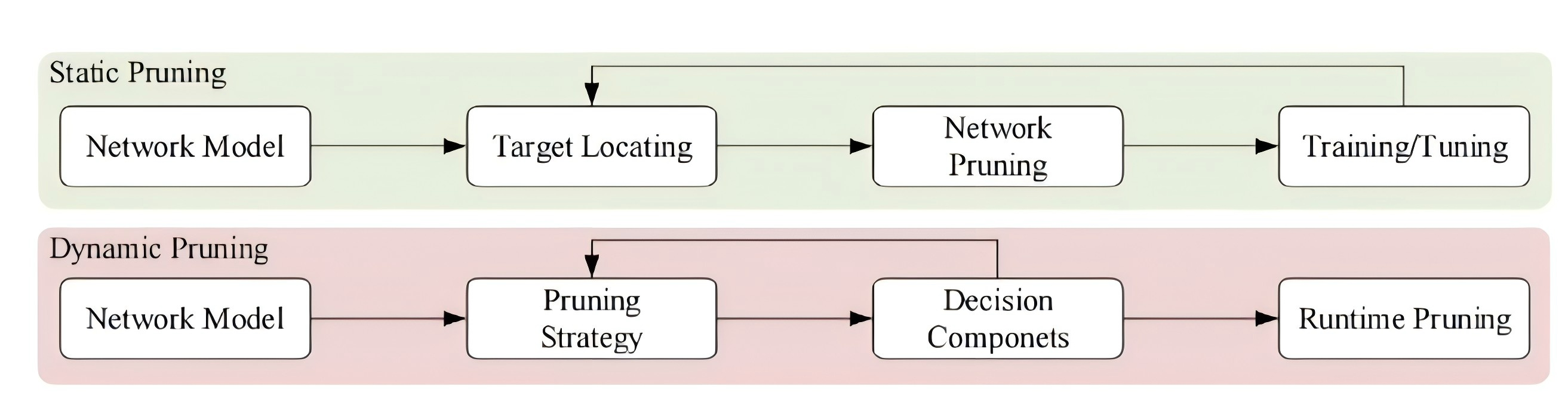
动态剪枝能够显著提高卷积神经网络的表达能力,从而在预测精度方面取得更好得性能。
动态剪枝也存在一些问题:
1:之前有方法通过强化学习来实现动态剪枝,但在训练过程中要消耗非常多的运算资源。
2:很多动态剪枝的方法都是通过强化学习的方式来实现的,但是”阀门的开关“,是不可微的,也就是说,梯度下降法在这里是用不了的。
3:存储成本高,不适用于资源有限的边缘设备。
1. 硬剪枝
在每个epoch后会将卷积核直接剪掉,被剪掉的卷积核在下一个epoch中不会再出现。
存在的问题:
1)模型性能降低;
2)依赖预先训练的模型。
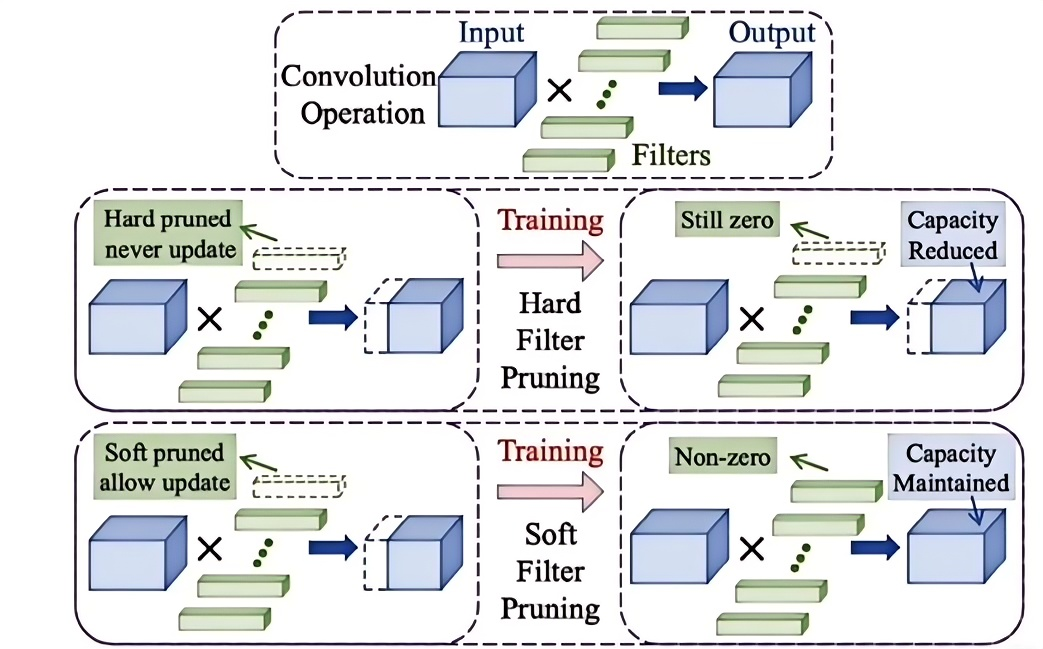
2. 软剪枝
相比较硬剪枝,软剪枝剪枝后进行训练时上一个epoch中被剪掉的卷积核在当前epoch训练时仍参与迭代,只是将其参数置为0,因此那些卷积核不会被直接丢弃。
一般有四个步骤:
- 滤波器选择
- 滤波器剪枝
- 重建
- 获得紧凑模型
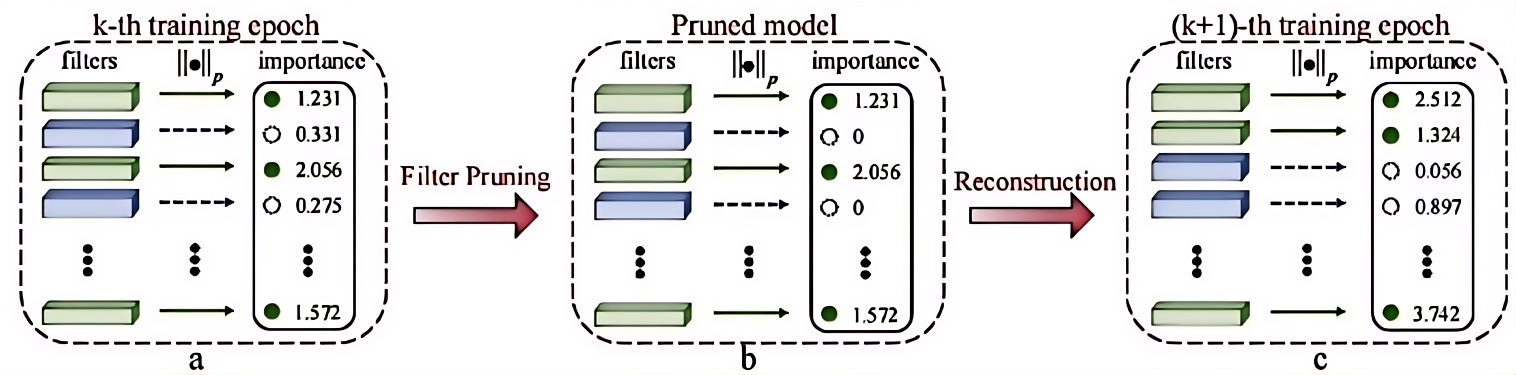
- 使用 L2 范数来评估每个滤波器的重要性,具有较小L2范数的滤波器的卷积结果会导致相对较低的激活值,从而对网络模型的最终预测结果有较小的影响,所以这种具有较小L2范数的滤波器更容易被剪掉。
- 将所选滤波器的值暂时设置为0,这可以暂时消除他们对网络输出的影响,但是在接下来的阶段,这些滤波器仍然可以被更新以保持模型的高性能,在滤波器剪枝过程中,可以同时修剪所有加权层,此外要对所有加权层使用相同的剪枝率。
- 在剪枝步骤之后,再训练一轮来重构修剪后的滤波器,修剪滤波器通过反向传播被更新为非0,这样经过软剪枝的模型可以具有和模型相当的性能。
- 获得一个紧凑模型,重复上述三个步骤
当模型收敛后,可以获得一个包含许多0滤波器的稀疏模型,一个0滤波器对应一个特征图,对应于那些0滤波器的特征图在推理过程中将总是0,移除这些滤波器以及相应的特征图不会有任何影响。
剪枝实践
SparseGPT






前提:该VGG每一层保证结构为:CONV->BN->RELU,每个BN层对应一个卷积层
L1正则化

取出所有BN中的$\gamma$值

对BN值排序,根据裁剪比例计算出保留的索引位置

剪枝,此时没有对原模型动刀,只是将不想要的权重部分通过mask置为0
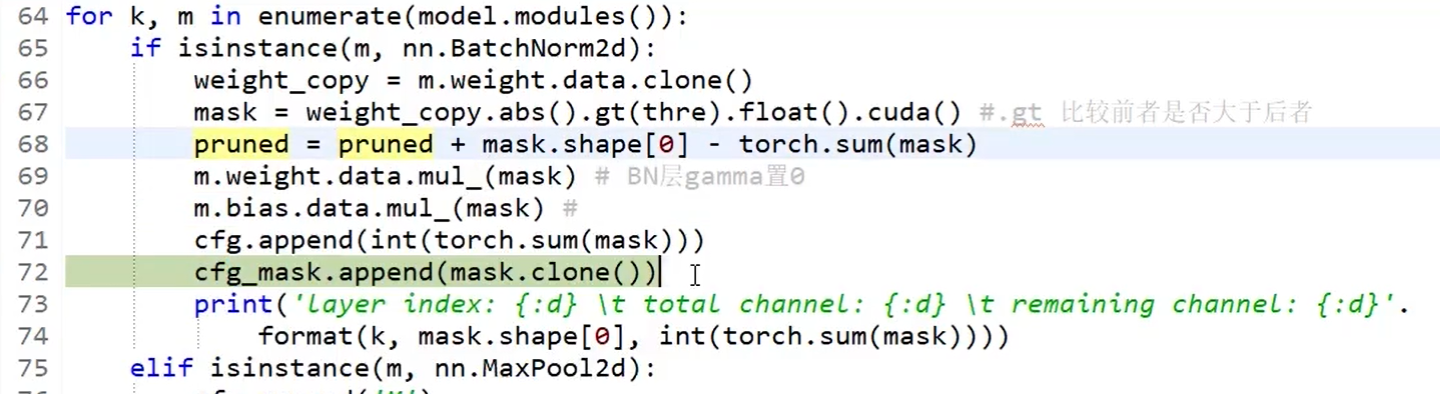
测试准确率,此时准确率将会出现大幅下降:
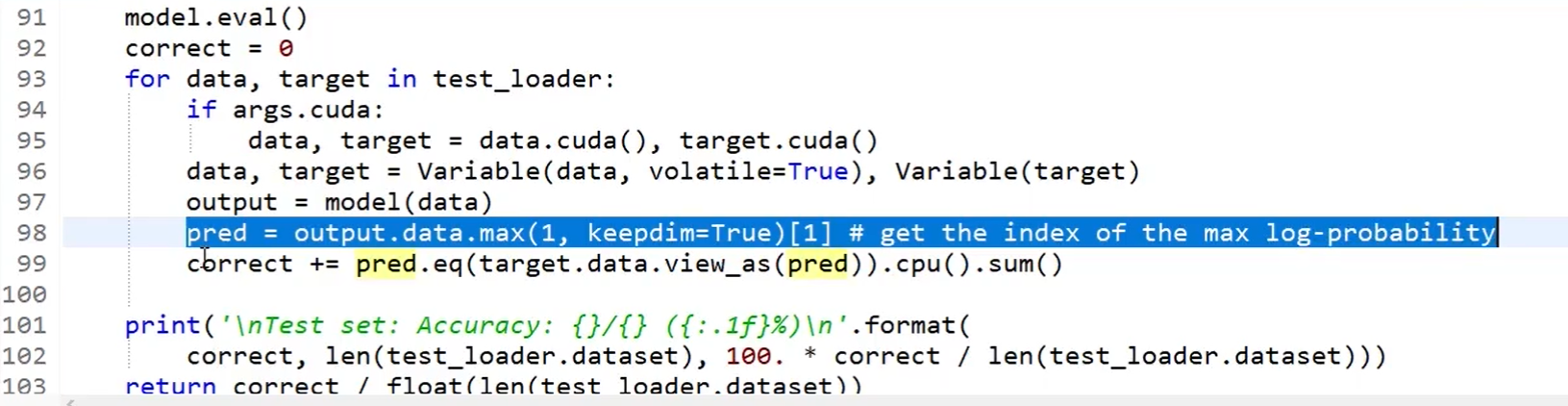
进行真正的剪枝:
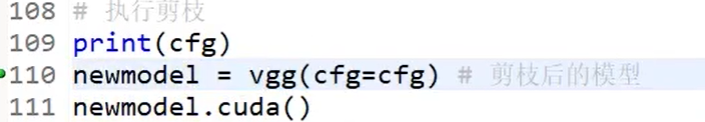


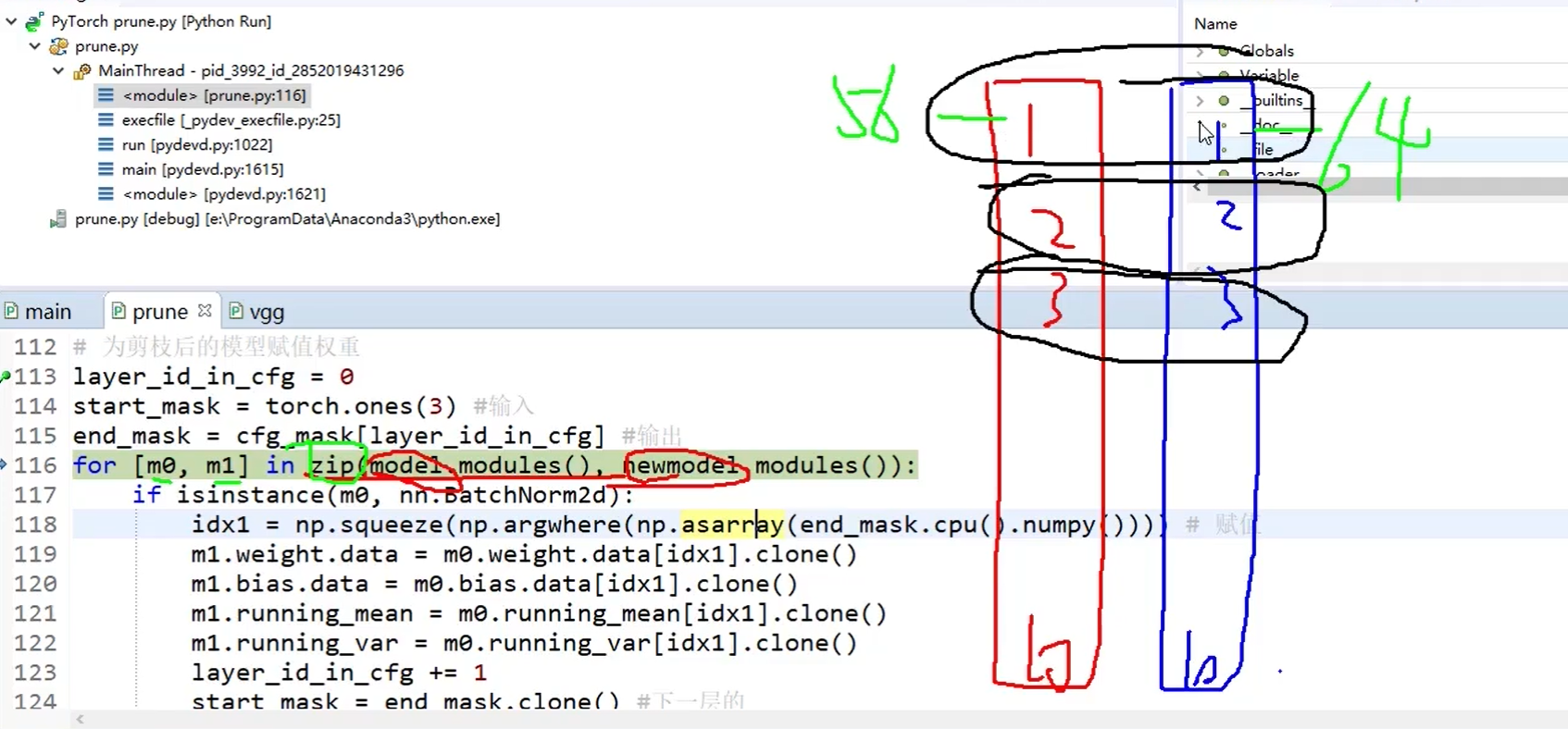
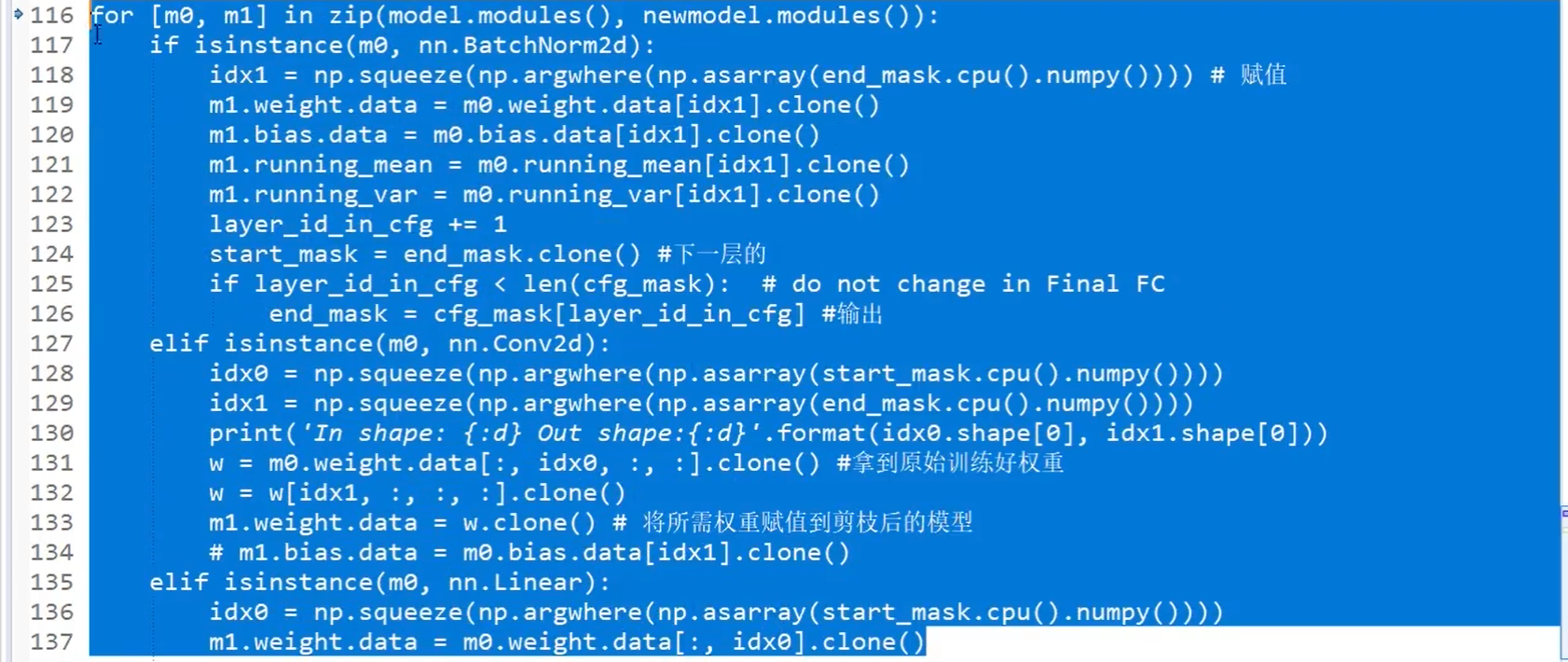
idx1 和 idx0是使用isinstance方法找到mask之后保留的参数位置。
我们要对每个卷积层mask掉一部分参数后的剪枝模型进行再训练,此时不需要正则化等操作,此时不希望进行稀疏化表示,不需要再次筛选:
剪枝策略
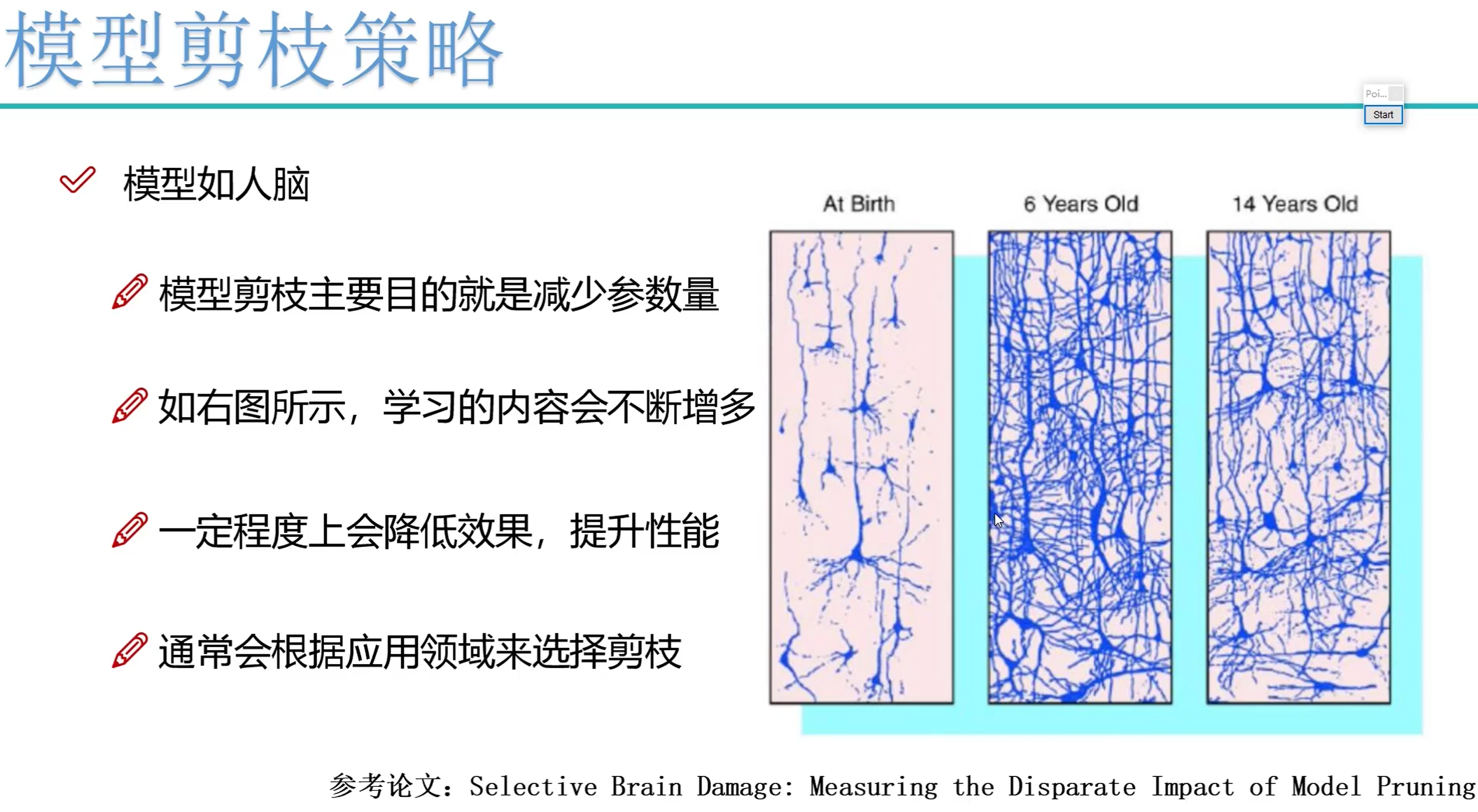
剪枝为什么会有效果呢?因为模型如人脑,丢弃掉一些无用的信息,专注在一些重要的信息上表现会更好。
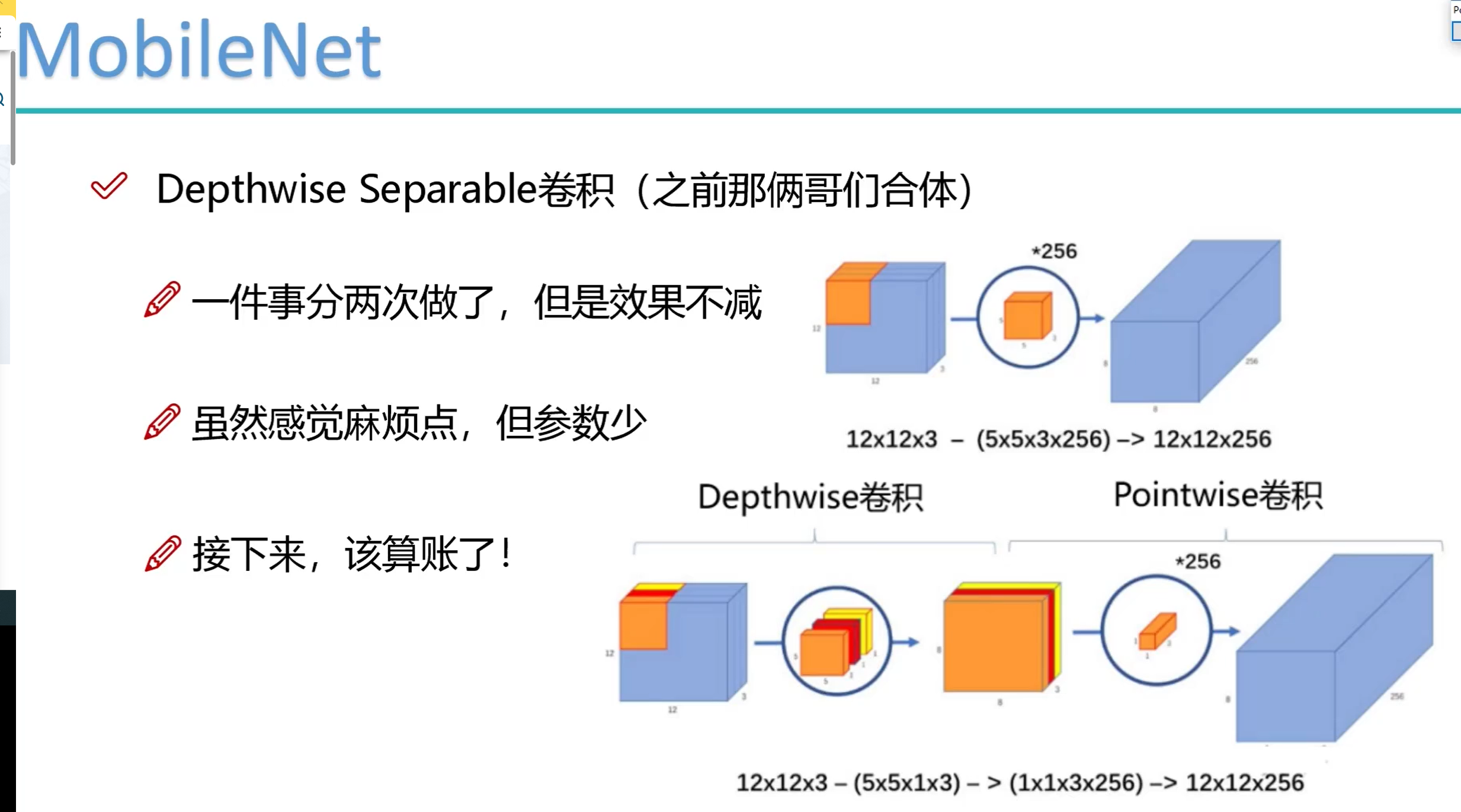


3. 知识蒸馏(Knowledge Distillation, KD)
知识蒸馏概念
-
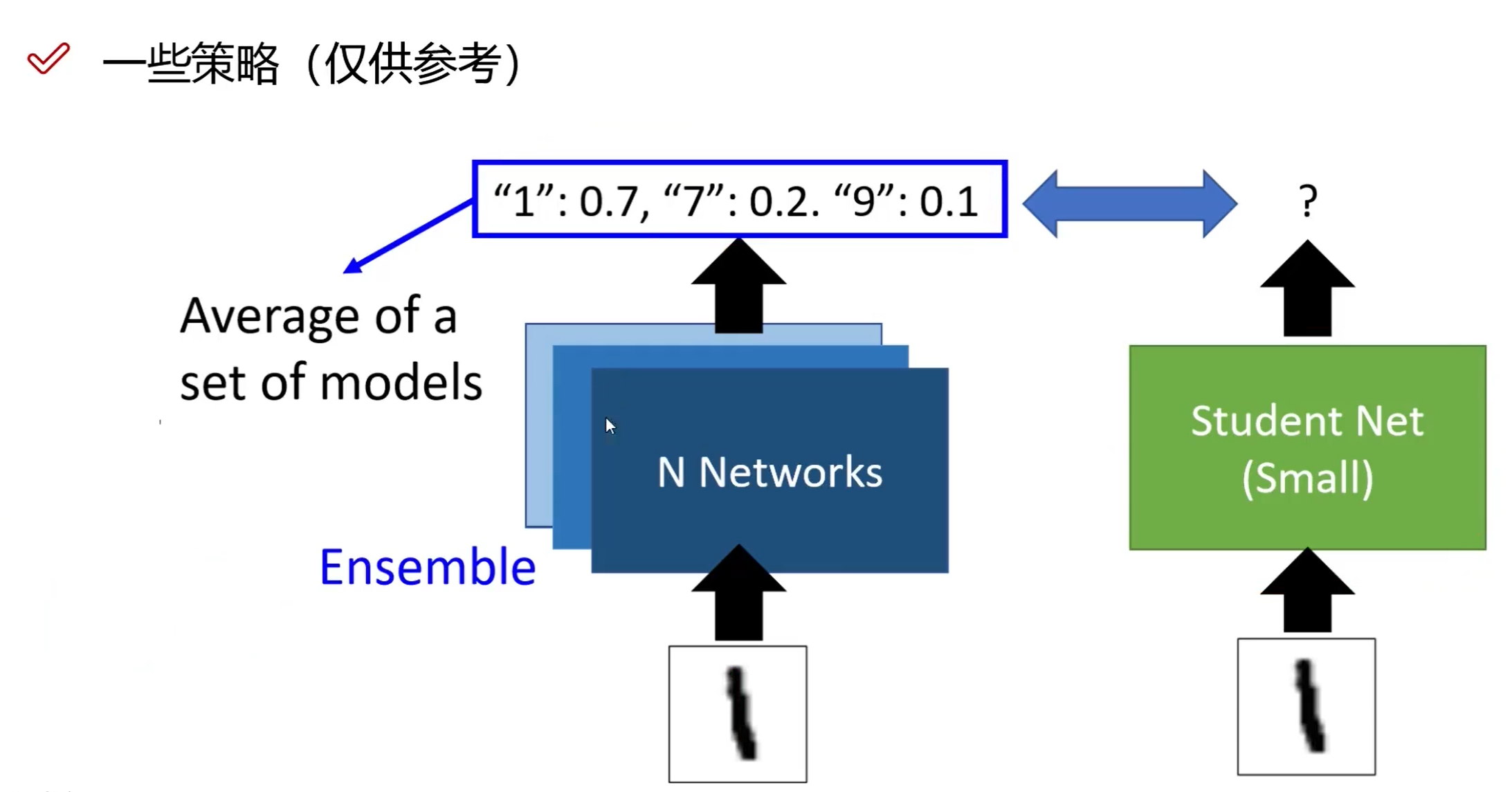
离线蒸馏(offline distillation):学生完全向老师学习
- step1: 蒸馏前,教师网络在训练集上进行训练
- step2: 教师网络通过logits层信息或者中间层信息,提取知识,引导学生网络进行训练
- 缺点:
- 教师网络比较庞大,模型复杂,需要大量的训练时间
- 需要注意学生网络和教师网络之间的差异,当差异过大时,学生网络可能很难学好这些知识
-
在线蒸馏(online distillation):学生和老师一起学习
- 教师网络和学生网络都是正在训练的状态,在没有现成的大教师网络模型的时候可以考虑
-
自蒸馏(self-distillation):学生自己学习
- 可以看成特殊的在线学习,教师模型和学生模型使用相同的模型
- 第一种是使用不用样本信息进行相互蒸馏,其他样本的软标签可以避免样本过拟合,甚至可以通过最小化不同样本间的预测分布来提高网络的性能
- 另一类是单个网络的网络层间进行自蒸馏,最通常的做法是使用深层网络的特征去指导浅层网络的学习
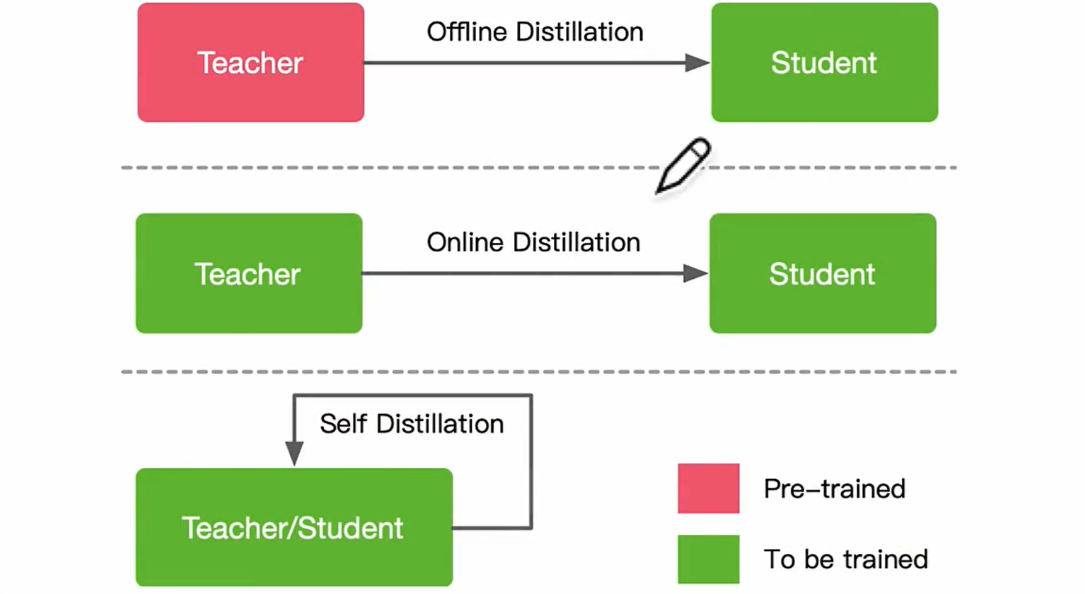
师生网络架构
学生网络一般是:
- 教师网络的简化版本,具有较少的层和每层中较少的信道。
- 教师网络的量化版本,其中网络的结构被保留。
- 具有高效基本操作的小型网络。
- 具有优化的整体网络结构的小型网络。
- 与教师相同的网络。
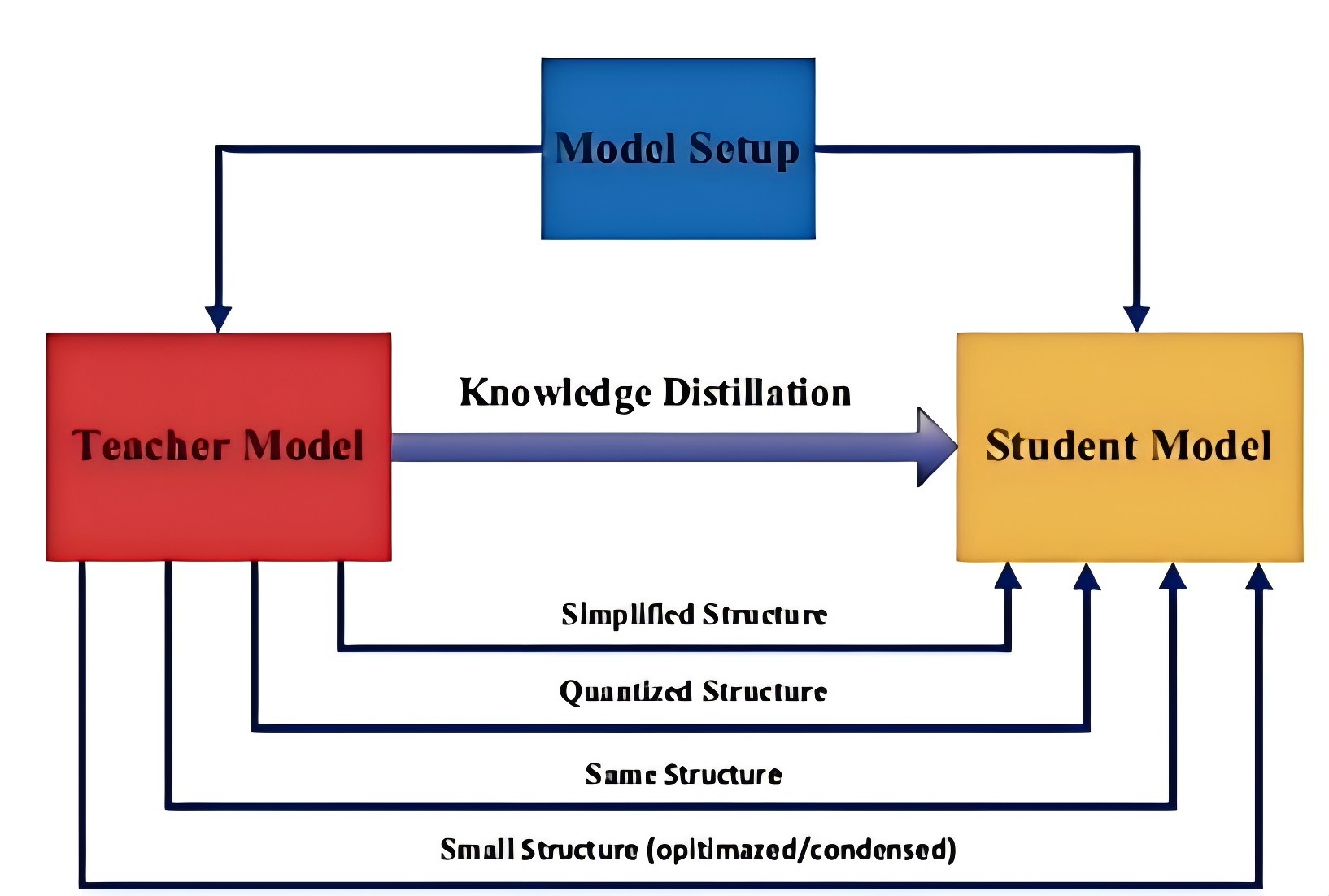
蒸馏流程
知识蒸馏可以分为4个步骤:
- 步骤一:训练教师模型。这个步骤非常简单。
- 步骤二:利用高温T产生教师网络和学生网络的Soft-target,用T=1产生学生网络的Hard-target。
- 步骤三:利用步骤二生成的Soft-target和Hard-target同时训练 Student 模型。
- 步骤四:设置T=1,Student模型做线上推理。
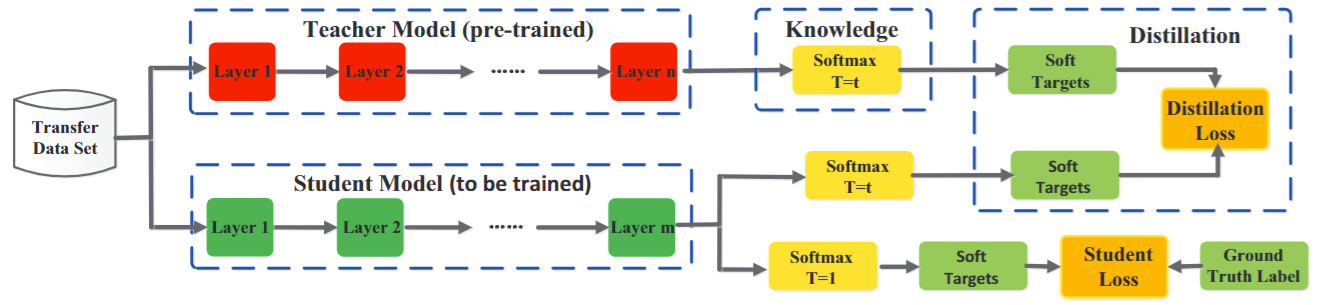
步骤二和步骤三统一称为高温蒸馏的过程,T为温度参数。总的损失函数L由Lsoft和Lhard加权得到。Lsoft 对应的是高温,Lhard对应的是T=1。Lsoft中的piT是教师模型在温度等于T的条件下 softmax 在第i类上的输出值,qiT是指学生模型在温度等于T的条件下 softmax 输出在第i类上的值。高温时,T的值很大,由指数函数图像很容易可以知道,T越大,不同类的概率差异会越小。
损失函数: $\mathrm{L}=\alpha \mathrm{L}{\text {soft }}+\beta \mathrm{L}{\text {hard }}$
其 中: $\quad \mathrm{L}{\text {sott }}=-\sum_i^N \mathrm{p}i^{\mathrm{T}} \log \left(\mathrm{q}{\mathrm{i}}^{\mathrm{T}}\right) \quad \mathrm{L}{\text {hard }}=-\sum_{\mathrm{i}}^N \mathrm{c}{\mathrm{i}} \log \left(\mathrm{q}{\mathrm{i}}^{\mathrm{l}}\right)$
而$\mathrm{p}{\mathrm{i}}^{\mathrm{T}}$是 Teacher 模型在温度等于T的条件下 softmax 输出在第i类上的值,$\mathrm{q}{\mathrm{i}}^{\mathrm{T}}$指是Student 模型在温度等于T的条件下 softmax 输出在第i类上的值。
$$
\mathrm{p}{\mathrm{i}}^{\mathrm{T}}=\frac{\exp \left(v_i / T\right)}{\sum_k^N \exp \left(v_k / T\right)} \quad \mathrm{q}{\mathrm{i}}^{\mathrm{T}}=\frac{\exp \left(z_i / T\right)}{\sum_k^N \exp \left(z_j / T\right)}
$$
下图中,soft predictions指包含除正确结果外的冗余信息(例如,图片识别为1【GT】,图片长得像7和9【冗余但是有用的信息】)。
-
soft loss 学生的预测结果与老师预测结果的loss
-
hard loss 学生预测结果与GT的比较
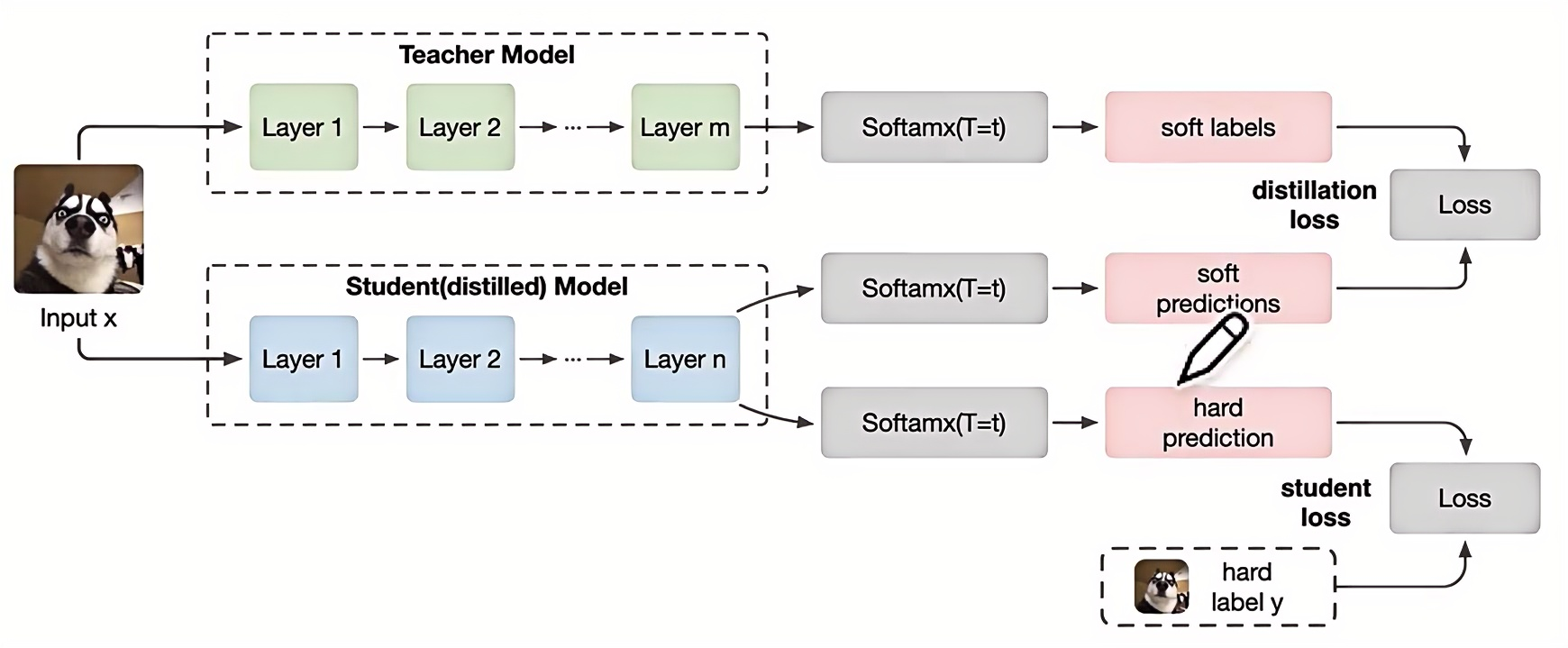
蒸馏算法
为了改进在更复杂的环境中传递知识的过程,已经出现了许多不同的知识蒸馏算法。下面,我们一起回顾知识蒸馏领域中最近提出的几种典型的蒸馏方法。
1. 对抗蒸馏
在对抗性学习中,对抗网络中的鉴别器用来估计样本来自训练数据分布的概率,而生成器试图使用生成的数据样本来欺骗鉴别器。受此启发,已经出现了许多基于对抗的知识蒸馏方法,以使教师和学生网络能够更好地理解真实的数据分布。
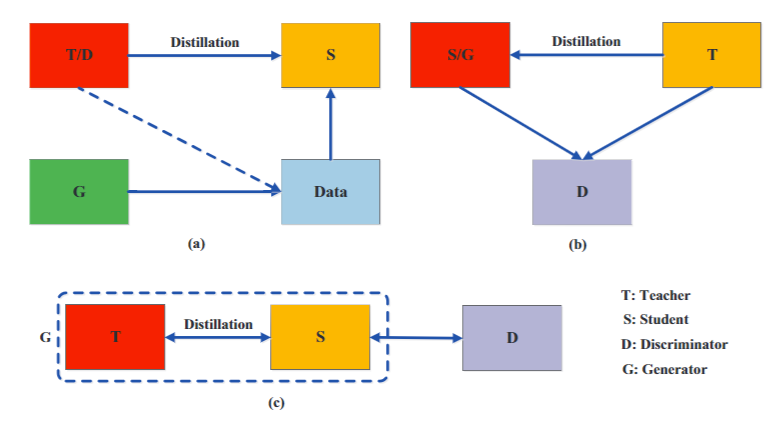
2. 多教师蒸馏
不同的教师架构可以为学生网络提供不同有用的知识。在训练学生网络期间,多个教师网络可以单独地,也可以整体地用于蒸馏。为了传递来自多个教师的知识,最简单的方法是使用来自所有教师的平均响应作为监督信号。
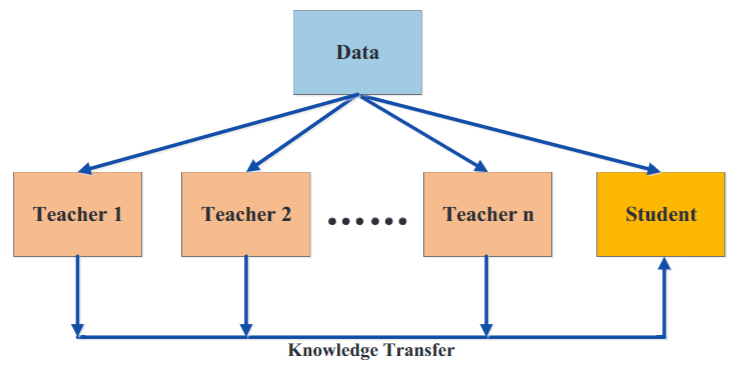
3. 交叉模式蒸馏
在训练或测试期间,某些数据或标签可能不可用。因此,在不同的模型之间传递知识是很重要的。然而,当模型存在差异时,跨模型知识蒸馏是一项具有挑战性的研究,例如当不同模式之间缺乏配对的样本时。
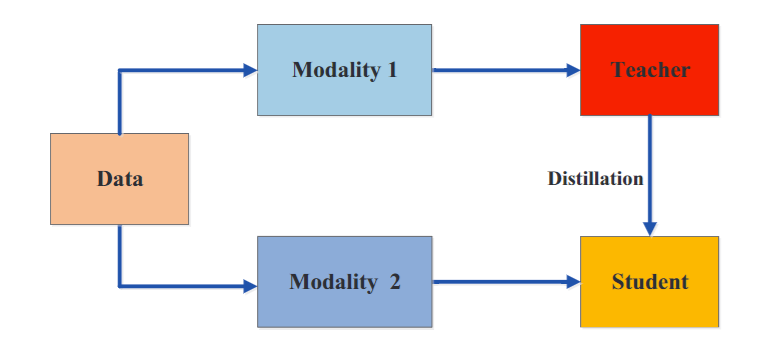
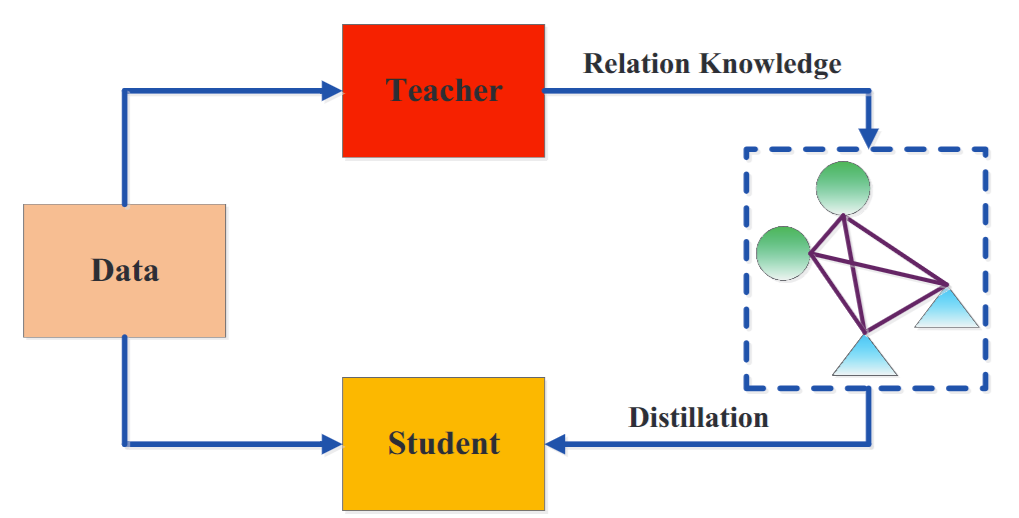
4. 基于图形的蒸馏
基于图的蒸馏方法的主要思想是
- 用图作为教师知识的载体;
- 用图来控制教师知识的信息传递。
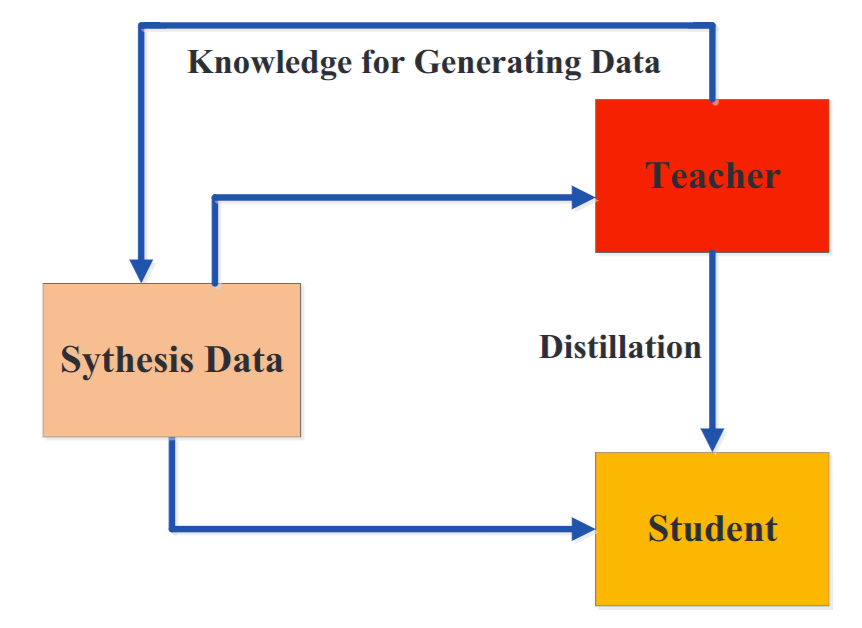
5. 无数据蒸馏
为了克服由隐私、合法性、安全性和保密性问题等原因引起的不可用数据的问题,出现了一些无数据知识蒸馏的方法。无数据蒸馏中的合成数据通常是从预训练教师模型的特征表示中生成的。
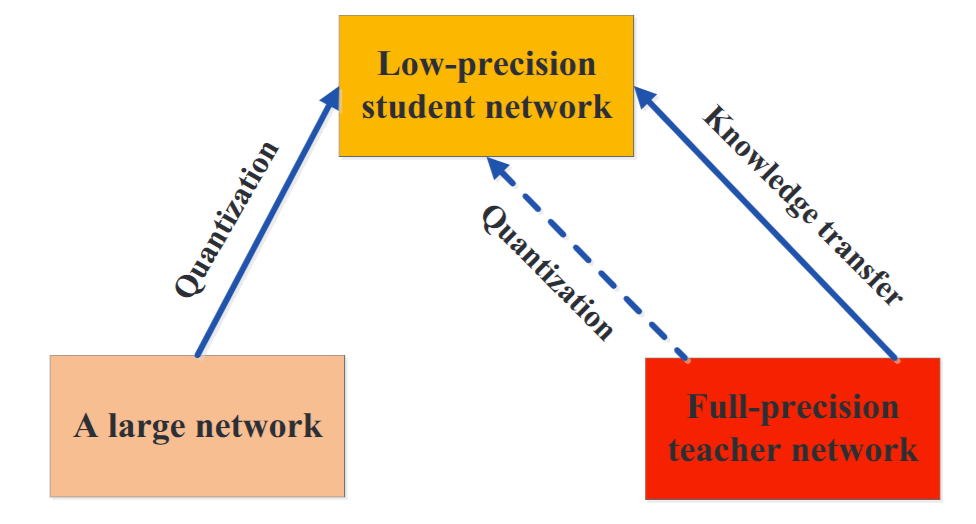
6. 量化蒸馏
一个大的高精度的教师网络将知识传递给一个小的低精度的学生网络。为了确保小的学生网络精确地模仿大的教师网络,首先在特征图上量化教师网络,然后将知识从量化的教师转移到量化的学生网络。
7. 其他知识蒸馏算法
基于注意力的蒸馏,终身蒸馏,NAS蒸馏。
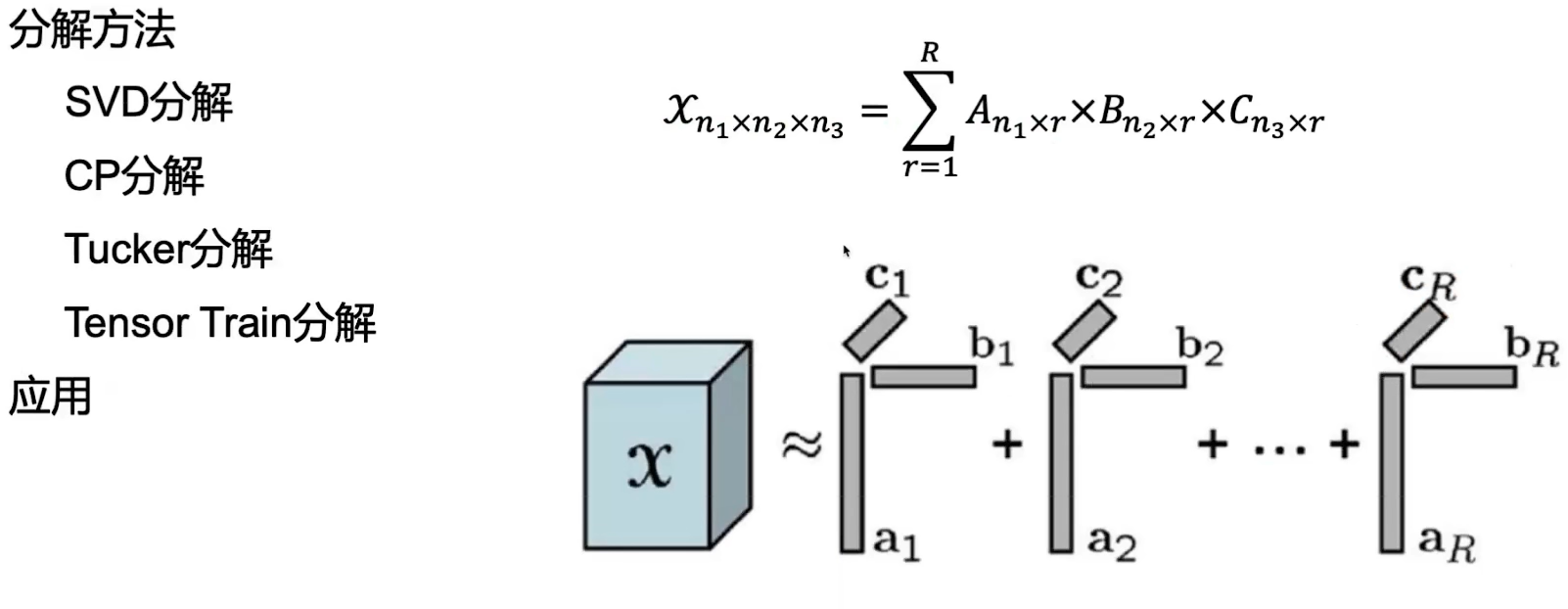
4. 低秩分解
卷积核矩阵的低秩特性,通过一些低秩的基础张量,去近似原始的大规模卷积核矩阵,低秩分解,它不仅能够降低存储空间的需求,也会降低计算复杂度。低秩分解的方法主要有奇异值分解,然后通过逼近的方式去求解这些,分解之后的矩阵,




